🚀 Wav2Vec2-XLS-R-300M-21-EN
このモデルは、FacebookによるWav2Vec2 XLS - Rを音声翻訳用にファインチューニングしたものです。音声を特定の言語から英語に翻訳することが可能で、多言語の音声データセットを用いて訓練されています。

🚀 クイックスタート
このモデルはSpeechEncoderDecoderModelです。エンコーダはfacebook/wav2vec2-xls-r-300mのチェックポイントからウォームスタートされ、デコーダはfacebook/mbart-large-50のチェックポイントから初期化されました。その後、Covost2データセットの21の{lang} -> enの翻訳ペアでファインチューニングされました。
このモデルは以下の音声言語から英語への翻訳が可能です。
{fr, de, es, ca, it, ru, zh-CN, pt, fa, et, mn, nl, tr, ar, sv-SE, lv, sl, ta, ja, id, cy} -> en
詳細については、公式XLS - R論文のセクション5.1.2を参照してください。
✨ 主な機能
- 多言語の音声を英語に翻訳することができます。
- エンコーダとデコーダがそれぞれ強力なモデルから初期化され、高精度な翻訳が期待できます。
📦 インストール
このモデルを使用するには、必要なライブラリをインストールする必要があります。以下のコマンドを使用してインストールできます。
pip install datasets transformers
💻 使用例
基本的な使用法
from datasets import load_dataset
from transformers import pipeline
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-300m-21-to-en")
translation = asr(audio_file)
高度な使用法
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
📚 ドキュメント
デモ
このモデルは、モデルカード上の音声認識ウィジェットで直接テストすることができます。可能な音声言語のいずれかで音声を録音するか、サンプルのオーディオファイルを選択して、チェックポイントが入力をどれだけうまく翻訳できるかを確認してください。
🔧 技術詳細
このモデルは、音声エンコーダとデコーダの組み合わせで構成されています。エンコーダは音声信号を特徴ベクトルに変換し、デコーダはその特徴ベクトルを英語のテキストに変換します。エンコーダとデコーダはそれぞれ事前学習されたモデルから初期化され、Covost2データセットを用いてファインチューニングされています。
📄 ライセンス
このモデルはapache-2.0ライセンスの下で提供されています。
その他の情報
| 属性 |
详情 |
| サポート言語 |
fr, de, es, ca, it, ru, zh-CN, pt, fa, et, mn, nl, tr, ar, sv-SE, lv, sl, ta, ja, id, cy から英語への翻訳 |
| データセット |
common_voice、multilingual_librispeech、covost2 |
| タグ |
speech、xls_r、automatic-speech-recognition、xls_r_translation |
| パイプラインタグ |
automatic-speech-recognition |
サンプルオーディオ
結果
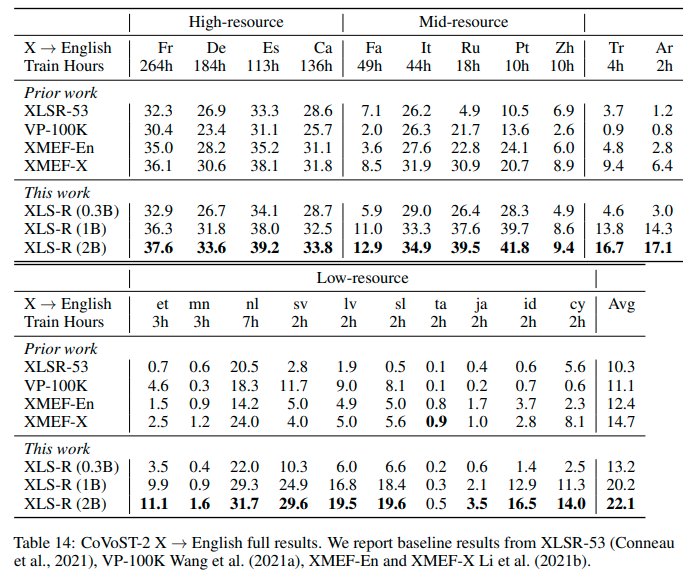
このモデルのCovost2でのパフォーマンスについては、XLS - R (0.3B) の行を参照してください。
その他のXLS - Rモデル
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応