🚀 Wav2Vec2-XLS-R-300M-EN-15
FacebookのWav2Vec2 XLS-Rを音声翻訳用にファインチューニングしたモデルです。このモデルは、英語の音声を複数の言語に翻訳することができ、音声翻訳タスクに適しています。

これはSpeechEncoderDecoderModelモデルです。エンコーダはfacebook/wav2vec2-xls-r-300mチェックポイントからウォームスタートされ、デコーダはfacebook/mbart-large-50チェックポイントから初期化されました。その結果、エンコーダ - デコーダモデルはCovost2データセットの15のen -> {lang}翻訳ペアでファインチューニングされました。
📦 インストール
このモデルを使用するには、必要なライブラリをインストールする必要があります。以下のコマンドを使用して、transformersとdatasetsライブラリをインストールできます。
pip install transformers datasets
✨ 主な機能
- 英語の音声を複数の言語に翻訳できます。
- エンコーダとデコーダのチェックポイントを利用して、効率的にファインチューニングされています。
- 標準的なシーケンス-to-シーケンストランスフォーマーモデルであり、
generateメソッドを使用して翻訳を生成できます。
💻 使用例
基本的な使用法
from datasets import load_dataset
from transformers import pipeline
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
forced_bos_token_id = MAPPING["sv"]
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-300m-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
高度な使用法
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token_id)
transcription = processor.batch_decode(generated_ids)
📚 ドキュメント
このモデルは、英語の音声を以下の書面言語に翻訳できます。
en -> {de, tr, fa, sv-SE, mn, zh-CN, cy, ca, sl, et, id, ar, ta, lv, ja}
詳細な情報については、公式XLS - R論文のセクション5.1.1を参照してください。
🔧 技術詳細
このモデルは、エンコーダとデコーダのチェックポイントを組み合わせて構築されています。エンコーダはfacebook/wav2vec2-xls-r-300mから初期化され、デコーダはfacebook/mbart-large-50から初期化されます。そして、Covost2データセットの15の翻訳ペアでファインチューニングされています。
📄 ライセンス
このモデルは、Apache 2.0ライセンスの下で提供されています。
🔍 その他の情報
デモ
このモデルはこのスペースでテストできます。ターゲット言語を選択し、英語で音声を録音して、チェックポイントが入力をどれだけうまく翻訳できるかを確認できます。
結果 en -> {lang}
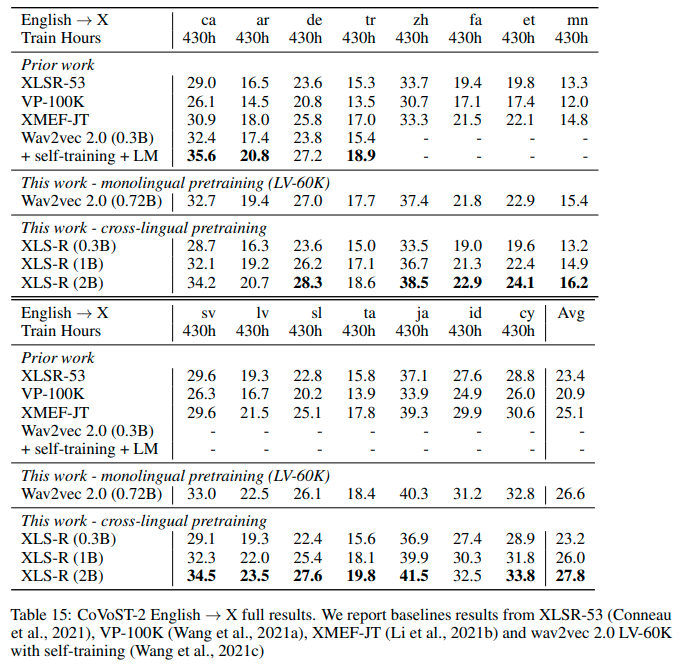
このモデルのCovost2でのパフォーマンスは、XLS - R (0.3B) の行を参照してください。
その他の{lang} -> en音声翻訳用XLS - Rモデル
📋 情報テーブル
| 属性 |
详情 |
| モデルタイプ |
SpeechEncoderDecoderModel |
| 学習データ |
common_voice、multilingual_librispeech、covost2 |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応