🚀 Segment Anything Model (SAM) - ViT Large (ViT-L) バージョン
Segment Anything Model (SAM) は、点やボックスなどの入力プロンプトから高品質なオブジェクトマスクを生成し、画像内のすべてのオブジェクトのマスクを生成するために使用できます。1100万枚の画像と11億個のマスクのデータセットで学習されており、さまざまなセグメンテーションタスクで強力なゼロショット性能を発揮します。
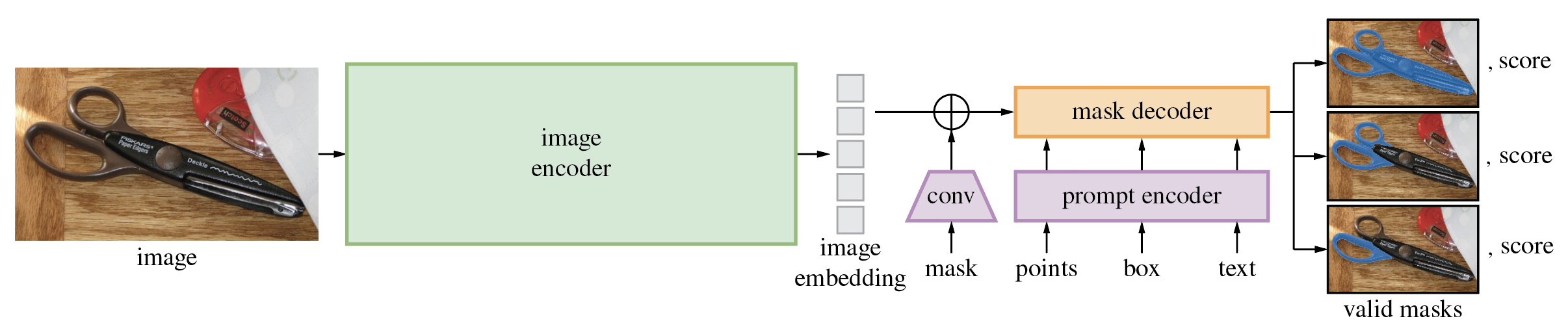 Segment Anything Model (SAM)の詳細なアーキテクチャ。
Segment Anything Model (SAM)の詳細なアーキテクチャ。
🚀 クイックスタート
目次
- TL;DR
- モデルの詳細
- 使用方法
- 引用
TL;DR
元のリポジトリへのリンク
Segment Anything Model (SAM) は、点やボックスなどの入力プロンプトから高品質なオブジェクトマスクを生成し、画像内のすべてのオブジェクトのマスクを生成するために使用できます。1100万枚の画像と11億個のマスクのデータセットで学習されており、さまざまなセグメンテーションタスクで強力なゼロショット性能を発揮します。
論文の要約には以下のように記載されています。
画像セグメンテーションのための新しいタスク、モデル、データセットであるSegment Anything (SA) プロジェクトを紹介します。データ収集ループで効率的なモデルを使用して、これまでで最大のセグメンテーションデータセットを構築しました(はるかに)、1100万枚のライセンス付きでプライバシーを尊重する画像に10億個以上のマスクが含まれています。このモデルは、プロンプト可能なように設計および学習されているため、新しい画像分布やタスクにゼロショットで適用できます。多数のタスクでその能力を評価し、ゼロショット性能が印象的であることを見出しました。多くの場合、従来の完全教師付きの結果と競合するか、さらにはそれを上回ります。コンピュータビジョンの基盤モデルの研究を促進するために、Segment Anything Model (SAM) と対応する10億個のマスクと1100万枚の画像のデータセット (SA-1B) を https://segment-anything.com で公開しています。
免責事項: この モデルカードの内容はHugging Faceチームによって作成されており、一部は元の SAMモデルカード からコピー&ペーストされています。
✨ 主な機能
SAMモデルは3つのモジュールで構成されています。
VisionEncoder:VITベースの画像エンコーダー。画像のパッチに対してアテンションを使用して画像埋め込みを計算します。相対位置埋め込みが使用されています。PromptEncoder:点とバウンディングボックスの埋め込みを生成します。MaskDecoder:画像埋め込みと点埋め込みの間(->)および点埋め込みと画像埋め込みの間でクロスアテンションを実行する双方向トランスフォーマー。出力はNeck:MaskDecoder によって生成されたコンテキスト化されたマスクに基づいて出力マスクを予測します。
💻 使用例
基本的な使用法
プロンプト付きマスク生成
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("facebook/sam-vit-large")
processor = SamProcessor.from_pretrained("facebook/sam-vit-large")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]]
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
マスクを生成するための他の引数の中で、関心のあるオブジェクトのおおよその位置の2D位置、関心のあるオブジェクトを囲むバウンディングボックス(形式はバウンディングボックスの右上と左下の点のx、y座標)、セグメンテーションマスクを渡すことができます。執筆時点では、公式のリポジトリによると、入力としてテキストを渡すことは公式モデルではサポートされていません。
詳細については、このノートブックを参照してください。これは、モデルの使用方法を視覚的な例で説明しています。
自動マスク生成
モデルは、入力画像を与えることで「ゼロショット」方式でセグメンテーションマスクを生成するために使用できます。モデルは自動的に 1024 個の点のグリッドでプロンプトされ、すべての点がモデルに入力されます。
このパイプラインは自動マスク生成用に作成されています。次のスニペットは、(任意のデバイスで!適切な points_per_batch 引数を渡すだけで)実行がいかに簡単であるかを示しています。
from transformers import pipeline
generator = pipeline("mask-generation", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
画像を表示するには、次のようにします。
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
📄 ライセンス
このモデルはApache-2.0ライセンスの下で提供されています。
📚 引用
このモデルを使用する場合は、次のBibTeXエントリを使用してください。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


 Transformers 複数言語対応
Transformers 複数言語対応