🚀 SlimSAM(SAMの圧縮版 = Segment Anything)のモデルカード
SlimSAMは、入力されたポイントやボックスなどのプロンプトから高品質なオブジェクトマスクを生成することができる、Segment Anything (SAM)モデルの圧縮(プルーニング)版です。
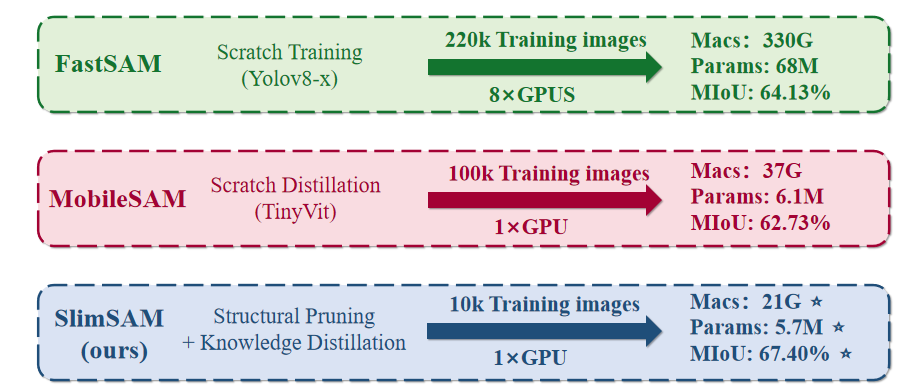 SlimSAMの概要と他のモデルとの違い。
SlimSAMの概要と他のモデルとの違い。
📚 目次
- 要約
- モデルの詳細
- 使用方法
- 引用
📋 要約
SlimSAMは、Segment Anything (SAM)モデルの圧縮(プルーニング)版であり、ポイントやボックスなどの入力プロンプトから高品質なオブジェクトマスクを生成することができます。
論文の概要には以下のように記載されています。
Segment Anything Model (SAM)の大きなモデルサイズと高い計算要件は、リソースが制限されたデバイスでの展開を困難にしています。既存のSAM圧縮アプローチは通常、ゼロから新しいネットワークをトレーニングすることを伴い、圧縮コストとモデル性能の間で難しいトレードオフをもたらします。この問題を解決するため、本論文では、非常に低いトレーニングコストで優れた性能を達成する新しいSAM圧縮方法であるSlimSAMを紹介します。これは、統一されたプルーニング・蒸留フレームワークを通じて事前学習されたSAMを効率的に再利用することで実現されます。元のSAMからの知識継承を強化するために、圧縮プロセスを段階的な手順に分割する革新的な交互スリミング戦略を採用しています。従来のプルーニング技術とは異なり、切り離されたモデル構造を交互に注意深くプルーニングし、蒸留します。さらに、新しいラベルフリーのプルーニング基準も提案されており、プルーニング目標を最適化ターゲットに合わせることで、プルーニング後の蒸留後の性能を向上させています。SlimSAMは、既存のどの方法よりも10倍以上少ないトレーニングコストで、大幅な性能向上をもたらします。元のSAM - Hと比較しても、SlimSAMは、パラメータ数をわずか0.9% (570万)、MACsを0.8% (21G)に削減し、SAMトレーニングデータのわずか0.1% (1万)しか必要とせず、近い性能を達成します。
元のリポジトリへのリンク
免責事項: このモデルカードの内容はHugging Faceチームによって作成されており、その一部は元のSAMモデルカードからコピー・ペーストされています。
📊 モデルの詳細
SAMモデルは3つのモジュールで構成されています。
VisionEncoder:VITベースの画像エンコーダーです。画像のパッチに対するアテンションを使用して画像埋め込みを計算します。相対位置埋め込みが使用されています。PromptEncoder:ポイントとバウンディングボックスの埋め込みを生成します。MaskDecoder:画像埋め込みとポイント埋め込みの間(->)、およびポイント埋め込みと画像埋め込みの間でクロスアテンションを実行する双方向トランスフォーマーです。出力はNeckに供給されます。Neck:MaskDecoderによって生成されたコンテキスト化されたマスクに基づいて出力マスクを予測します。
💻 使用方法
🔍 プロンプト付きマスク生成
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("nielsr/slimsam-50-uniform")
processor = SamProcessor.from_pretrained("nielsr/slimsam-50-uniform")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]]
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
マスクを生成するための他の引数の中で、関心のあるオブジェクトのおおよその位置の2D座標、関心のあるオブジェクトを囲むバウンディングボックス(形式はバウンディングボックスの右上と左下の点のx、y座標)、セグメンテーションマスクを渡すことができます。執筆時点では、公式リポジトリによると、公式モデルでは入力としてテキストを渡すことはサポートされていません。
詳細については、このノートブックを参照してください。これは、モデルの使用方法を視覚的な例で示しています。
🤖 自動マスク生成
このモデルは、入力画像を与えることで、「ゼロショット」方式でセグメンテーションマスクを生成するために使用できます。モデルは自動的に1024個のポイントのグリッドでプロンプトされ、すべてがモデルに供給されます。
このパイプラインは自動マスク生成用に作られています。次のコードスニペットは、(どのデバイスでも!適切なpoints_per_batch引数を渡すだけで)実行がいかに簡単かを示しています。
from transformers import pipeline
generator = pipeline(task="mask-generation", model="nielsr/slimsam-50-uniform", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
画像を表示するには、次のようにします。
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
📄 引用
このモデルを使用する場合は、次のBibTeXエントリを使用してください。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
@misc{chen202301,
title={0.1% Data Makes Segment Anything Slim},
author={Zigeng Chen and Gongfan Fang and Xinyin Ma and Xinchao Wang},
year={2023},
eprint={2312.05284},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応