%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
JA
Mme5 Mllama 11b Instruct
mmE5はLlama-3.2-11B-Visionでトレーニングされたマルチモーダル多言語埋め込みモデルで、高品質な合成データにより埋め込み性能を向上させ、MMEBベンチマークで最先端のレベルを達成しました。
ダウンロード数 596
リリース時間 : 2/13/2025
モデル概要
このモデルはマルチモーダル(画像+テキスト)および多言語埋め込みタスクに特化しており、画像とテキストを統一された埋め込み空間にマッピングし、クロスモーダル検索と類似度計算をサポートします。
モデル特徴
マルチモーダル埋め込み能力
画像とテキスト入力を同時に処理し、それらを統一された埋め込み空間にマッピングできます
多言語サポート
英語、中国語、アラビア語など8言語のテキスト処理をサポート
高品質合成データによるトレーニング
特別に設計された合成データを使用してトレーニングし、モデル性能を向上
最先端の性能
MMEBベンチマークで最先端のレベルを達成
モデル能力
画像-テキスト類似度計算
クロスモーダル検索
多言語テキスト埋め込み
ゼロショット画像分類
使用事例
クロスモーダル検索
画像検索
テキストクエリで関連画像を検索
例:'猫と犬'のクエリと画像のマッチ度0.4219
テキスト検索
画像で関連テキスト記述を検索
例:画像と'猫と犬'のテキストマッチ度0.4414
多言語アプリケーション
多言語画像注釈
画像に対して多言語の説明やラベルを生成
🚀 mmE5-mllama-11b-instruct
このモデルは、多言語多モーダル埋め込みを高品質な合成データを用いて改善するためのモデルです。Llama-3.2-11B-Vision をベースに訓練されています。
🚀 クイックスタート
このモデルは、多言語多モーダル埋め込みのタスクに使用できます。以下のセクションでは、モデルの使用方法や実験結果などを紹介します。
✨ 主な機能
- 多言語対応: 英語、アラビア語、中国語、韓国語、ロシア語、ポーランド語、トルコ語、フランス語などの言語に対応しています。
- ゼロショット画像分類: 事前に学習していないクラスに対しても画像分類が可能です。
- SOTA性能: MMEBベンチマークにおいてSOTA性能を達成しています。
📦 インストール
このモデルを使用するには、transformers ライブラリをインストールする必要があります。以下のコマンドでインストールできます。
pip install transformers
💻 使用例
基本的な使用法
以下は、transformers ライブラリを使用した基本的な使用例です。
import torch
import requests
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
# Pooling and Normalization
def last_pooling(last_hidden_state, attention_mask, normalize=True):
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_state.shape[0]
reps = last_hidden_state[torch.arange(batch_size, device=last_hidden_state.device), sequence_lengths]
if normalize:
reps = torch.nn.functional.normalize(reps, p=2, dim=-1)
return reps
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
model_name = "intfloat/mmE5-mllama-11b-instruct"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(model_name)
model = MllamaForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.bfloat16
).to("cuda")
model.eval()
# Image + Text -> Text
image = Image.open(requests.get('https://github.com/haon-chen/mmE5/blob/main/figures/example.jpg?raw=true', stream=True).raw)
inputs = processor(text='<|image|><|begin_of_text|>Represent the given image with the following question: What is in the image\n', images=[image], return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = 'A cat and a dog'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**text_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], text_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.4219]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**text_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], text_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.3184]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.\n', return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = '<|image|><|begin_of_text|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[image], return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**tgt_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], tgt_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|>Represent the given image. = tensor([[0.4414]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.\n', return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = '<|image|><|begin_of_text|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[image], return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**tgt_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], tgt_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|>Represent the given image. = tensor([[0.3730]], device='cuda:0', dtype=torch.bfloat16)
高度な使用法
Sentence Transformers を使用することで、前処理と後処理の大部分を抽象化することができます。
from sentence_transformers import SentenceTransformer
import requests
# Load the model
model = SentenceTransformer("intfloat/mmE5-mllama-11b-instruct", trust_remote_code=True)
# Download an example image of a cat and a dog
dog_cat_image_bytes = requests.get('https://github.com/haon-chen/mmE5/blob/main/figures/example.jpg?raw=true', stream=True).raw.read()
with open("cat_dog_example.jpg", "wb") as f:
f.write(dog_cat_image_bytes)
# Image + Text -> Text
image_embeddings = model.encode([{
"image": "cat_dog_example.jpg",
"text": "Represent the given image with the following question: What is in the image",
}])
text_embeddings = model.encode([
{"text": "A cat and a dog"},
{"text": "A cat and a tiger"},
])
similarity = model.similarity(image_embeddings, text_embeddings)
print(similarity)
# tensor([[0.3967, 0.3090]])
# ✅ The first text is most similar to the image
# Text -> Image
image_embeddings = model.encode([
{"image": dog_cat_image_bytes, "text": "Represent the given image."},
])
text_embeddings = model.encode([
{"text": "Find me an everyday image that matches the given caption: A cat and a dog."},
{"text": "Find me an everyday image that matches the given caption: A cat and a tiger."},
])
similarity = model.similarity(image_embeddings, text_embeddings)
print(similarity)
# tensor([[0.4250, 0.3896]])
# ✅ The first text is most similar to the image
📚 ドキュメント
論文情報
mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data. Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, Zhicheng Dou, arXiv 2025
ソースコード
訓練/評価データ
- 訓練データ: https://huggingface.co/datasets/intfloat/mmE5-MMEB-hardneg, https://huggingface.co/datasets/intfloat/mmE5-synthetic
- 評価データ: https://huggingface.co/datasets/TIGER-Lab/MMEB-eval, https://huggingface.co/datasets/Haon-Chen/XTD-10
実験結果
このモデルは、MMEBベンチマークにおいてSOTA性能を達成しています。以下は実験結果の画像です。
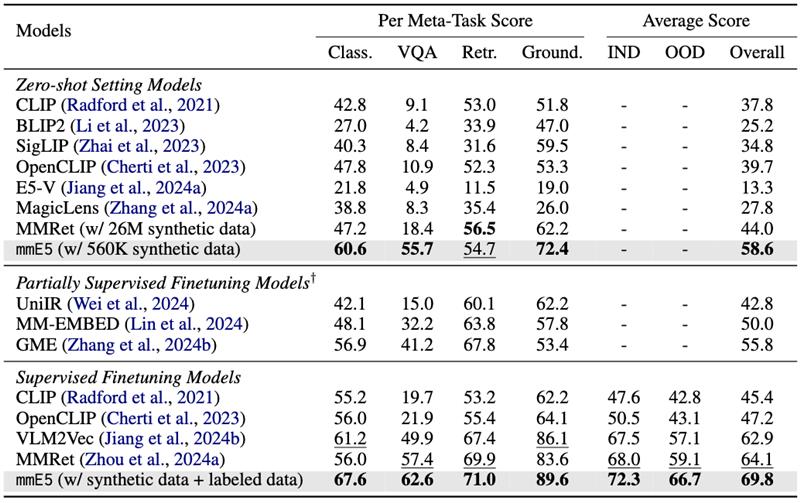
🔧 技術詳細
このモデルは、Llama-3.2-11B-Vision をベースに訓練されています。多言語多モーダル埋め込みのタスクに特化しており、高品質な合成データを用いて訓練されています。
📄 ライセンス
このモデルは、MITライセンスの下で公開されています。
引用
@article{chen2025mmE5,
title={mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data},
author={Chen, Haonan and Wang, Liang and Yang, Nan and Zhu, Yutao and Zhao, Ziliang and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2502.08468},
year={2025}
}
Codebert Base
CodeBERTはプログラミング言語と自然言語向けの事前学習モデルで、RoBERTaアーキテクチャに基づいており、コード検索やコードからドキュメント生成などの機能をサポートします。
マルチモーダル融合
C
microsoft
1.6M
248
Llama 4 Scout 17B 16E Instruct
その他
Llama 4 ScoutはMetaが開発したマルチモーダルAIモデルで、混合専門家アーキテクチャを採用し、12言語のテキストと画像インタラクションをサポート、17Bの活性化パラメータと109Bの総パラメータを有します。
マルチモーダル融合 Transformers 複数言語対応
Transformers 複数言語対応
L
meta-llama
817.62k
844
Unixcoder Base
Apache-2.0
UniXcoderは統一されたマルチモーダル事前学習モデルで、コードコメントや抽象構文木などのマルチモーダルデータを使用してコード表現を事前学習します。
マルチモーダル融合 Transformers 英語
U
microsoft
347.45k
51
TITAN
TITANは、病理学画像分析のための視覚的自己教師あり学習と視覚-言語アライメントによるマルチモーダル全スライド基礎モデルです。
マルチモーダル融合 Safetensors 英語
Safetensors 英語
Safetensors 英語T
MahmoodLab
213.39k
37
Qwen2.5 Omni 7B
その他
Qwen2.5-Omniはエンドツーエンドのマルチモーダルモデルで、テキスト、画像、音声、ビデオなど様々なモダリティを認識し、ストリーミング方式でテキストや自然な音声レスポンスを生成できます。
マルチモーダル融合 Transformers 英語
Q
Qwen
206.20k
1,522
Minicpm O 2 6
MiniCPM-o 2.6はスマートフォンで動作するGPT-4oレベルのマルチモーダル大規模モデルで、視覚、音声、ライブストリーム処理をサポート
マルチモーダル融合 Transformers その他
M
openbmb
178.38k
1,117
Llama 4 Scout 17B 16E Instruct
その他
Llama 4 ScoutはMetaが開発した17Bパラメータ/16エキスパート混合のマルチモーダルAIモデルで、12言語と画像理解をサポートし、業界をリードする性能を有しています。
マルチモーダル融合 Transformers 複数言語対応
L
chutesai
173.52k
2
Qwen2.5 Omni 3B
その他
Qwen2.5-Omniはエンドツーエンドのマルチモーダルモデルで、テキスト、画像、音声、ビデオなど様々なモダリティ情報を認識し、ストリーミング方式でテキストと自然な音声応答を同期生成できます。
マルチモーダル融合 Transformers 英語
Q
Qwen
48.07k
219
One Align
MIT
Q-Alignはマルチタスク視覚評価モデルで、画像品質評価(IQA)、美的評価(IAA)、動画品質評価(VQA)に特化しており、ICML2024で発表されました。
マルチモーダル融合 Transformers
O
q-future
39.48k
25
Biomedvlp BioViL T
MIT
BioViL-Tは胸部X線画像と放射線レポートの分析に特化した視覚言語モデルで、時系列マルチモーダル事前学習により性能を向上させています。
マルチモーダル融合 Transformers 英語
B
microsoft
26.39k
35
おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98