🚀 GLM-4-Z1-32B-0414
The GLM-4-Z1-32B-0414 series is a new generation of open - source models in the GLM family. With 32 billion parameters, it offers comparable performance to OpenAI's GPT series and DeepSeek's V3/R1 series. It also supports highly user - friendly local deployment features. This README provides an in - depth introduction to the model, its usage guidelines, inference code, and citation information.
✨ Features
Model Introduction
- GLM - 4 - 32B - 0414 Series: Pre - trained on 15T of high - quality data, including a large amount of reasoning - type synthetic data. In the post - training stage, techniques such as rejection sampling and reinforcement learning were used to enhance performance in instruction following, engineering code, and function calling. It performs well in engineering code, Artifact generation, function calling, search - based Q&A, and report generation.
- GLM - Z1 - 32B - 0414: A reasoning model with deep thinking capabilities. Developed based on GLM - 4 - 32B - 0414 through cold start and extended reinforcement learning, and further trained on mathematics, code, and logic tasks. Significantly improves mathematical abilities and the capability to solve complex tasks.
- GLM - Z1 - Rumination - 32B - 0414: A deep reasoning model with rumination capabilities. Employs longer periods of deep thought, integrates search tools during the thinking process, and is trained using multiple rule - based rewards to handle complex tasks. Shows significant improvements in research - style writing and complex retrieval tasks.
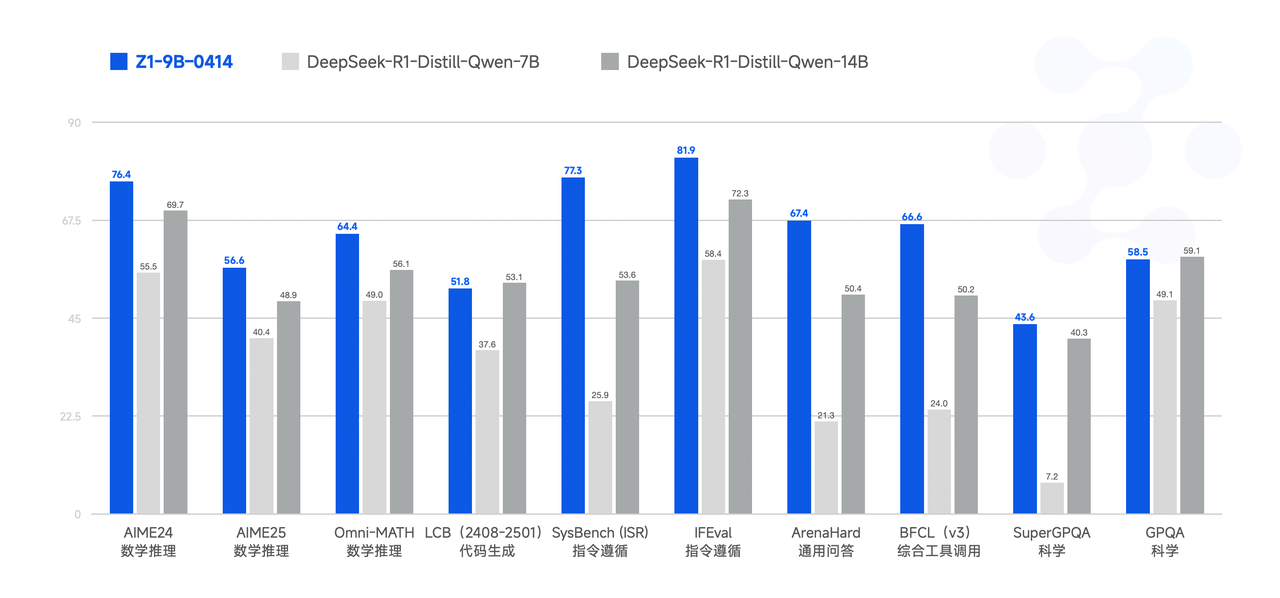
- GLM - Z1 - 9B - 0414: A 9B small - sized model maintaining the open - source tradition. Exhibits excellent capabilities in mathematical reasoning and general tasks, achieving a good balance between efficiency and effectiveness in resource - constrained scenarios.
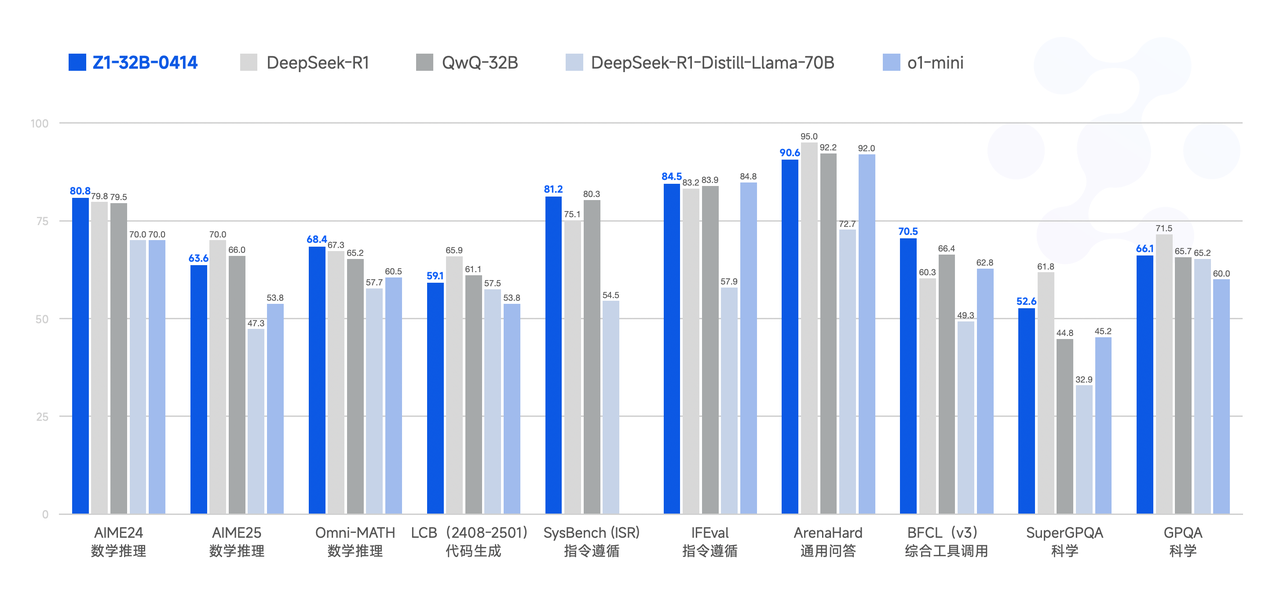
Performance
The model achieves good results in various benchmarks, with some benchmarks even rivaling larger models like GPT - 4o and DeepSeek - V3 - 0324 (671B).
📦 Installation
Make sure to use transformers>=4.51.3. You can install the required library using the following command:
pip install transformers>=4.51.3
💻 Usage Examples
Basic Usage
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
📚 Documentation
I. Sampling Parameters
| Property |
Details |
| temperature |
0.6. Balances creativity and stability. |
| top_p |
0.95. Cumulative probability threshold for sampling. |
| top_k |
40. Filters out rare tokens while maintaining diversity. |
| max_new_tokens |
30000. Leaves enough tokens for thinking. |
II. Enforced Thinking
- Add
<think>\n to the first line to ensure the model thinks before responding.
- When using
chat_template.jinja, the prompt is automatically injected to enforce this behavior.
III. Dialogue History Trimming
- Retain only the final user - visible reply.
- Hidden thinking content should not be saved to history to reduce interference. This is already implemented in
chat_template.jinja.
IV. Handling Long Contexts (YaRN)
- When input length exceeds 8,192 tokens, consider enabling YaRN (Rope Scaling).
- In supported frameworks, add the following snippet to
config.json:
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
- Static YaRN applies uniformly to all text. It may slightly degrade performance on short texts, so enable as needed.
📄 License
This project is licensed under the MIT license.
📚 Citations
If you find our work useful, please consider citing the following paper.
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers Supports Multiple LanguagesOpen Source License:MIT#Deep Reasoning#Mathematical Enhancement#Function Calling
Transformers Supports Multiple LanguagesOpen Source License:MIT#Deep Reasoning#Mathematical Enhancement#Function Calling