🚀 EMOVA-Qwen-2.5-3B
EMOVA-Qwen-2.5-3B is a novel end - to - end omni - modal LLM. It can handle textual, visual, and speech inputs, generating both textual and speech responses with emotional controls. This model has excellent performance in various benchmarks and supports bilingual spoken dialogue.
✨ Features
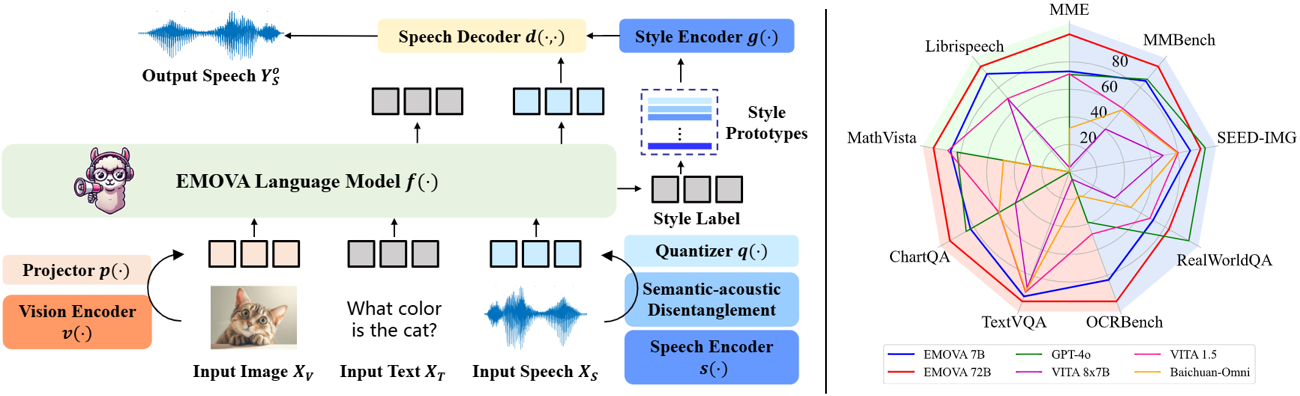
EMOVA (EMotionally Omni - present Voice Assistant) is a novel end - to - end omni - modal LLM that can see, hear and speak without relying on external models. Given the omni - modal (i.e., textual, visual and speech) inputs, EMOVA can generate both textual and speech responses with vivid emotional controls by utilizing the speech decoder together with a style encoder. EMOVA possesses general omni - modal understanding and generation capabilities, featuring its superiority in advanced vision - language understanding, emotional spoken dialogue, and spoken dialogue with structural data understanding. Its key advantages are summarized as follows:
- State - of - the - art omni - modality performance: EMOVA achieves state - of - the - art comparable results on both vision - language and speech benchmarks simultaneously. Our best - performing model, EMOVA - 72B, even surpasses commercial models including GPT - 4o and Gemini Pro 1.5.
- Emotional spoken dialogue: A semantic - acoustic disentangled speech tokenizer and a lightweight style control module are adopted for seamless omni - modal alignment and diverse speech style controllability. EMOVA supports bilingual (Chinese and English) spoken dialogue with 24 speech style controls (i.e., 2 speakers, 3 pitches and 4 emotions).
- Diverse configurations: We open - source 3 configurations, EMOVA - 3B/7B/72B, to support omni - modal usage under different computational budgets. Check our Model Zoo and find the best - fit model for your computational devices!
📊 Performance
| Benchmarks |
EMOVA - 3B |
EMOVA - 7B |
EMOVA - 72B |
GPT - 4o |
VITA 8x7B |
VITA 1.5 |
Baichuan - Omni |
| MME |
2175 |
2317 |
2402 |
2310 |
2097 |
2311 |
2187 |
| MMBench |
79.2 |
83.0 |
86.4 |
83.4 |
71.8 |
76.6 |
76.2 |
| SEED - Image |
74.9 |
75.5 |
76.6 |
77.1 |
72.6 |
74.2 |
74.1 |
| MM - Vet |
57.3 |
59.4 |
64.8 |
- |
41.6 |
51.1 |
65.4 |
| RealWorldQA |
62.6 |
67.5 |
71.0 |
75.4 |
59.0 |
66.8 |
62.6 |
| TextVQA |
77.2 |
78.0 |
81.4 |
- |
71.8 |
74.9 |
74.3 |
| ChartQA |
81.5 |
84.9 |
88.7 |
85.7 |
76.6 |
79.6 |
79.6 |
| DocVQA |
93.5 |
94.2 |
95.9 |
92.8 |
- |
- |
- |
| InfoVQA |
71.2 |
75.1 |
83.2 |
- |
- |
- |
- |
| OCRBench |
803 |
814 |
843 |
736 |
678 |
752 |
700 |
| ScienceQA - Img |
92.7 |
96.4 |
98.2 |
- |
- |
- |
- |
| AI2D |
78.6 |
81.7 |
85.8 |
84.6 |
73.1 |
79.3 |
- |
| MathVista |
62.6 |
65.5 |
69.9 |
63.8 |
44.9 |
66.2 |
51.9 |
| Mathverse |
31.4 |
40.9 |
50.0 |
- |
- |
- |
- |
| Librispeech (WER↓) |
5.4 |
4.1 |
2.9 |
- |
3.4 |
8.1 |
- |
💻 Usage
This repo contains the EMOVA - Qwen2.5 - 3B checkpoint organized in the original format of our EMOVA codebase, and thus, it should be utilized together with EMOVA codebase. Its paired config file is provided here. Check here to launch a web demo using this checkpoint.
📚 Documentation
Model Information
| Property |
Details |
| Library Name |
transformers |
| Tags |
Omni - modal - LLM, Multi - modal - LLM, Emotional - spoken - dialogue |
| License |
apache - 2.0 |
| Datasets |
Emova - ollm/emova - alignment - 7m, Emova - ollm/emova - sft - 4m, Emova - ollm/emova - sft - speech - 231k |
| Languages |
en, zh |
| Base Model |
Emova - ollm/qwen2vit600m, Emova - ollm/Qwen2.5 - 3B - Instruct_add_speech_token_4096_nostrip |
| New Version |
Emova - ollm/emova - qwen - 2 - 5 - 3b - hf |
Model Index
- Name: emova - qwen - 2 - 5 - 3b - hf
- Results:
- Multimodal Tasks:
- AI2D: Accuracy = 78.6%
- ChartQA: Accuracy = 81.5%
- DocVQA: Accuracy = 93.5%
- InfoVQA: Accuracy = 71.2%
- MathVerse: Accuracy = 31.4%
- MathVista: Accuracy = 62.6%
- MMBench: Accuracy = 79.2%
- MME: Score = 2175
- MMVet: Accuracy = 57.3%
- OCRBench: Accuracy = 803
- RealWorldQA: Accuracy = 62.6%
- Seed - Bench - Image: Accuracy = 74.9%
- Science - QA: Accuracy = 92.7%
- TextVQA: Accuracy = 77.2%
- Automatic Speech Recognition:
- LibriSpeech (clean): Test WER = 5.4
📄 License
This project is licensed under the apache - 2.0 license.
📖 Citation
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors