%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 Wav2Vec2-Large-XLSR-53-Arabic
This model is a fine - tuned version of facebook/wav2vec2-large-xlsr-53 on Arabic. It uses the train splits of Common Voice and Arabic Speech Corpus. When using this model, ensure that your speech input is sampled at 16kHz.
✨ Features
- Datasets: Trained on
arabic_speech_corpusandmozilla - foundation/common_voice_6_1. - Metrics: Evaluated using Word Error Rate (WER).
- Tags: Related to audio, automatic speech recognition, and more.
- License: Licensed under Apache - 2.0.
| Property | Details |
|---|---|
| Model Type | Wav2Vec2 - Large - XLSR - 53 - Arabic |
| Training Data | arabic_speech_corpus, mozilla - foundation/common_voice_6_1 |
🚀 Quick Start
The model can be used directly (without a language model) as follows:
💻 Usage Examples
Basic Usage
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("common_voice", "ar", split="test[:10]")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
dataset = dataset.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["sentence"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", buckwalter.untrans(predicted))
print("--")
Here's the output:
reference: ألديك قلم ؟
predicted: هلديك قالر
--
reference: ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.
predicted: ليست نالك مسافة على هذه الأرض أبعد من يوم أمس
--
reference: إنك تكبر المشكلة.
predicted: إنك تكبر المشكلة
--
reference: يرغب أن يلتقي بك.
predicted: يرغب أن يلتقي بك
--
reference: إنهم لا يعرفون لماذا حتى.
predicted: إنهم لا يعرفون لماذا حتى
--
reference: سيسعدني مساعدتك أي وقت تحب.
predicted: سيسئدني مساعد سكرأي وقت تحب
--
reference: أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة.
predicted: أحب ناضريةً علمية إلي هي أنحل قتزح المكونا بالكامل من الأمت عن المفقودة
--
reference: سأشتري له قلماً.
predicted: سأشتري له قلما
--
reference: أين المشكلة ؟
predicted: أين المشكل
--
reference: وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ
predicted: ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون
--
🔧 Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
import jiwer
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import set_seed, Wav2Vec2ForCTC, Wav2Vec2Processor
set_seed(42)
test_split = load_dataset("common_voice", "ar", split="test")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_split = test_split.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").to("cuda").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values.to("cuda")).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.batch_decode(predicted)
return batch
test_split = test_split.map(predict, batched=True, batch_size=16, remove_columns=["speech"])
transformation = jiwer.Compose([
# normalize some diacritics, remove punctuation, and replace Persian letters with Arabic ones
jiwer.SubstituteRegexes({
r'[auiFNKo\~_،؟»\?;:\-,\.؛«!"]': "", "\u06D6": "",
r"[\|\{]": "A", "p": "h", "ک": "k", "ی": "y"}),
# default transformation below
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.SentencesToListOfWords(),
jiwer.RemoveEmptyStrings(),
])
metrics = jiwer.compute_measures(
truth=[buckwalter.trans(s) for s in test_split["sentence"]], # Buckwalter transliteration
hypothesis=test_split["predicted"],
truth_transform=transformation,
hypothesis_transform=transformation,
)
print(f"WER: {metrics['wer']:.2%}")
Test Result: 26.55%
🔧 Training
For more details, see [Fine - Tuning with Arabic Speech Corpus](https://github.com/huggingface/transformers/tree/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2#fine - tuning - with - arabic - speech - corpus).
This model represents Arabic in a format called Buckwalter transliteration. The Buckwalter format only includes ASCII characters, some of which are non - alpha (e.g., ">" maps to "أ"). The [lang - trans](https://github.com/kariminf/lang - trans) package is used to convert (transliterate) Arabic abjad.
This script was used to first fine - tune [facebook/wav2vec2 - large - xlsr - 53](https://huggingface.co/facebook/wav2vec2 - large - xlsr - 53) on the train split of the Arabic Speech Corpus dataset; the test split was used for model selection; the resulting model at this point is saved as [elgeish/wav2vec2 - large - xlsr - 53 - levantine - arabic](https://huggingface.co/elgeish/wav2vec2 - large - xlsr - 53 - levantine - arabic).
Training was then resumed using the train split of the Common Voice dataset; the validation split was used for model selection; training was stopped to meet the deadline of Fine - Tune - XLSR Week: this model is the checkpoint at 100k steps and a validation WER of 23.39%.
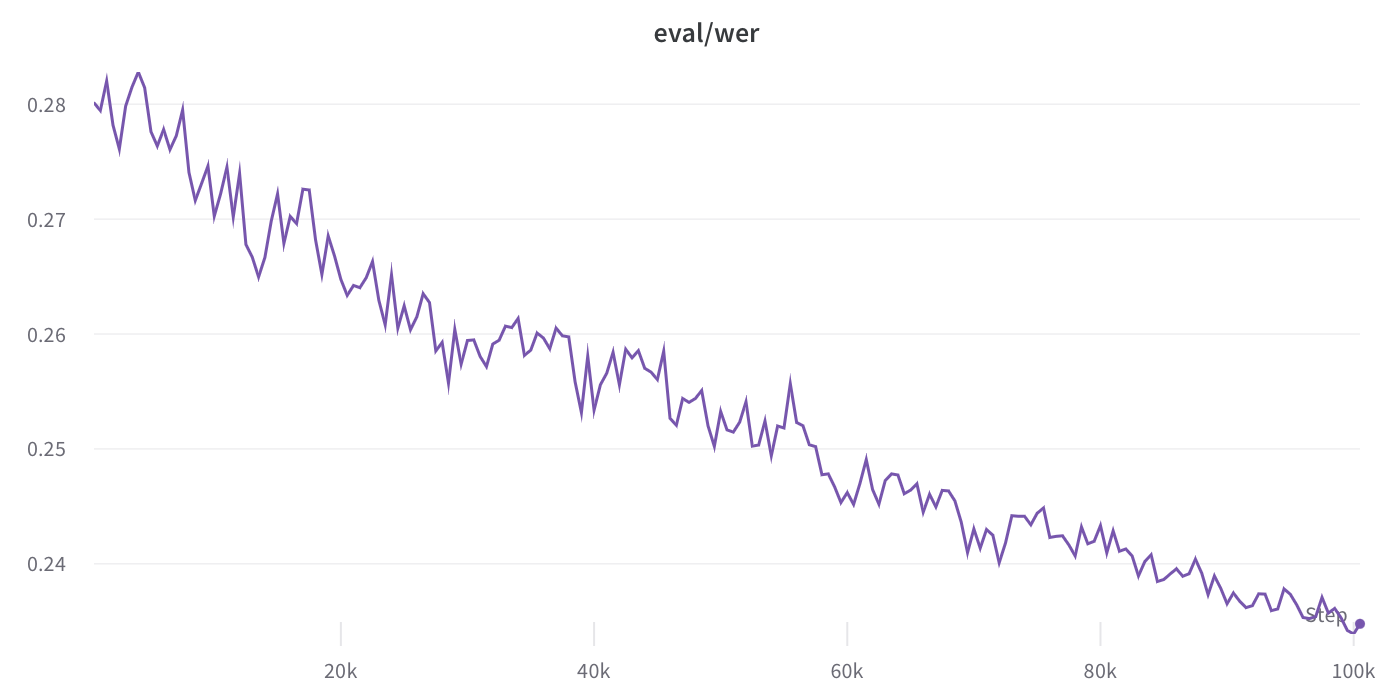
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e - 6).
💡 Future Work
One area to explore is using attention_mask in model input, which is recommended [here](https://huggingface.co/blog/fine - tune - xlsr - wav2vec2). Also, exploring data augmentation using datasets used to train models listed [here](https://paperswithcode.com/sota/speech - recognition - on - common - voice - arabic).
📄 License
This model is licensed under the Apache - 2.0 license.