%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
Gliclass Edge V3.0
GLiClass是一款高效的零样本分类器,性能与交叉编码器相当但计算效率更高,适用于多任务场景。
下载量 105
发布时间 : 7/20/2025
模型介绍
内容详情
替代品
模型简介
通用轻量级序列分类模型,支持零样本分类、主题分类、情感分析及RAG管道重排,通过LoRA适配器微调保留知识。
模型特点
高效零样本分类
单次前向传播完成分类,计算效率优于交叉编码器
多任务适配
支持主题分类、情感分析及RAG重排等多种任务
逻辑推理能力
在逻辑任务上训练以增强推理能力
知识保留微调
使用LoRA适配器避免破坏预训练知识
模型能力
文本分类
自然语言推理
情感分析
零样本学习
多标签分类
使用案例
内容分类
新闻主题分类
对新闻文本进行多标签主题分类
在20_news_groups数据集F1达0.5958
情感分析
产品评论情感分析
分析用户评论的情感倾向
在sst2数据集F1达0.9192
RAG增强
检索结果重排序
作为RAG管道的重排组件
🚀 GLiClass:用于序列分类的通用轻量级模型
GLiClass是一款高效的零样本分类器,灵感源自GLiNER。它在性能上与交叉编码器相当,但计算效率更高,因为分类只需一次前向传播。该模型可用于主题分类、情感分析,还能作为RAG管道中的重排器。此外,模型在逻辑任务上进行训练以诱导推理能力,并使用LoRA适配器进行微调,避免破坏先前学习的知识。

🚀 快速开始
安装GLiClass库
pip install gliclass
pip install -U transformers>=4.48.0
初始化模型和管道
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-edge-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-edge-v3.0", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
NLI任务使用示例
若要将其用于NLI类型的任务,建议将前提表示为文本,假设表示为标签。可以输入多个假设,但模型在单个假设输入时效果最佳。
# 初始化模型和多标签管道
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
✨ 主要特性
- 高效零样本分类:受GLiNER工作启发,在单次前向传播中完成分类,性能与交叉编码器相当,但计算效率更高。
- 多任务应用:可用于
主题分类、情感分析,还能作为RAG管道中的重排器。 - 逻辑推理诱导:在逻辑任务上进行训练,以诱导推理能力。
- 知识保留微调:使用LoRA适配器进行微调,避免破坏先前学习的知识。
📦 安装指南
pip install gliclass
pip install -U transformers>=4.48.0
💻 使用示例
基础用法
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-edge-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-edge-v3.0", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
高级用法
# 用于NLI类型任务的示例
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
📚 详细文档
模型信息
| 属性 | 详情 |
|---|---|
| 模型类型 | 用于序列分类的通用轻量级模型 |
| 训练数据集 | BioMike/formal-logic-reasoning-gliclass-2k、knowledgator/gliclass-v3-logic-dataset、tau/commonsense_qa |
| 评估指标 | F1 |
| 标签 | 文本分类、自然语言推理、情感分析 |
| 管道标签 | 文本分类 |
LoRA参数
| gliclass‑modern‑base‑v3.0 | gliclass‑modern‑large‑v3.0 | gliclass‑base‑v3.0 | gliclass‑large‑v3.0 | |
|---|---|---|---|---|
| LoRa r | 512 | 768 | 384 | 384 |
| LoRa α | 1024 | 1536 | 768 | 768 |
| focal loss α | 0.7 | 0.7 | 0.7 | 0.7 |
| 目标模块 | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" |
GLiClass-V3模型
| 模型名称 | 大小 | 参数数量 | 平均基准分数 | 平均推理速度 (batch size = 1, a6000, 示例/秒) |
|---|---|---|---|---|
| gliclass‑edge‑v3.0 | 131 MB | 32.7M | 0.4873 | 97.29 |
| gliclass‑modern‑base‑v3.0 | 606 MB | 151M | 0.5571 | 54.46 |
| gliclass‑modern‑large‑v3.0 | 1.6 GB | 399M | 0.6082 | 43.80 |
| gliclass‑base‑v3.0 | 746 MB | 187M | 0.6556 | 51.61 |
| gliclass‑large‑v3.0 | 1.75 GB | 439M | 0.7001 | 25.22 |
基准测试
以下是几个文本分类数据集上的F1分数。所有测试模型均未在这些数据集上进行微调,而是在零样本设置下进行测试。
GLiClass-V3模型
| 数据集 | gliclass‑large‑v3.0 | gliclass‑base‑v3.0 | gliclass‑modern‑large‑v3.0 | gliclass‑modern‑base‑v3.0 | gliclass‑edge‑v3.0 |
|---|---|---|---|---|---|
| CR | 0.9398 | 0.9127 | 0.8952 | 0.8902 | 0.8215 |
| sst2 | 0.9192 | 0.8959 | 0.9330 | 0.8959 | 0.8199 |
| sst5 | 0.4606 | 0.3376 | 0.4619 | 0.2756 | 0.2823 |
| 20_news_groups | 0.5958 | 0.4759 | 0.3905 | 0.3433 | 0.2217 |
| spam | 0.7584 | 0.6760 | 0.5813 | 0.6398 | 0.5623 |
| financial_phrasebank | 0.9000 | 0.8971 | 0.5929 | 0.4200 | 0.5004 |
| imdb | 0.9366 | 0.9251 | 0.9402 | 0.9158 | 0.8485 |
| ag_news | 0.7181 | 0.7279 | 0.7269 | 0.6663 | 0.6645 |
| emotion | 0.4506 | 0.4447 | 0.4517 | 0.4254 | 0.3851 |
| cap_sotu | 0.4589 | 0.4614 | 0.4072 | 0.3625 | 0.2583 |
| rotten_tomatoes | 0.8411 | 0.7943 | 0.7664 | 0.7070 | 0.7024 |
| massive | 0.5649 | 0.5040 | 0.3905 | 0.3442 | 0.2414 |
| banking | 0.5574 | 0.4698 | 0.3683 | 0.3561 | 0.0272 |
| AVERAGE | 0.7001 | 0.6556 | 0.6082 | 0.5571 | 0.4873 |
先前的GLiClass模型
| 数据集 | gliclass‑large‑v1.0‑lw | gliclass‑base‑v1.0‑lw | gliclass‑modern‑large‑v2.0 | gliclass‑modern‑base‑v2.0 |
|---|---|---|---|---|
| CR | 0.9226 | 0.9097 | 0.9154 | 0.8977 |
| sst2 | 0.9247 | 0.8987 | 0.9308 | 0.8524 |
| sst5 | 0.2891 | 0.3779 | 0.2152 | 0.2346 |
| 20_news_groups | 0.4083 | 0.3953 | 0.3813 | 0.3857 |
| spam | 0.3642 | 0.5126 | 0.6603 | 0.4608 |
| financial_phrasebank | 0.9044 | 0.8880 | 0.3152 | 0.3465 |
| imdb | 0.9429 | 0.9351 | 0.9449 | 0.9188 |
| ag_news | 0.7559 | 0.6985 | 0.6999 | 0.6836 |
| emotion | 0.3951 | 0.3516 | 0.4341 | 0.3926 |
| cap_sotu | 0.4749 | 0.4643 | 0.4095 | 0.3588 |
| rotten_tomatoes | 0.8807 | 0.8429 | 0.7386 | 0.6066 |
| massive | 0.5606 | 0.4635 | 0.2394 | 0.3458 |
| banking | 0.3317 | 0.4396 | 0.1355 | 0.2907 |
| AVERAGE | 0.6273 | 0.6291 | 0.5400 | 0.5211 |
交叉编码器
| 数据集 | deberta‑v3‑large‑zeroshot‑v2.0 | deberta‑v3‑base‑zeroshot‑v2.0 | roberta‑large‑zeroshot‑v2.0‑c | comprehend_it‑base |
|---|---|---|---|---|
| CR | 0.9134 | 0.9051 | 0.9141 | 0.8936 |
| sst2 | 0.9272 | 0.9176 | 0.8573 | 0.9006 |
| sst5 | 0.3861 | 0.3848 | 0.4159 | 0.4140 |
| enron_spam | 0.5970 | 0.4640 | 0.5040 | 0.3637 |
| financial_phrasebank | 0.5820 | 0.6690 | 0.4550 | 0.4695 |
| imdb | 0.9180 | 0.8990 | 0.9040 | 0.4644 |
| ag_news | 0.7710 | 0.7420 | 0.7450 | 0.6016 |
| emotion | 0.4840 | 0.4950 | 0.4860 | 0.4165 |
| cap_sotu | 0.5020 | 0.4770 | 0.5230 | 0.3823 |
| rotten_tomatoes | 0.8680 | 0.8600 | 0.8410 | 0.4728 |
| massive | 0.5180 | 0.5200 | 0.5200 | 0.3314 |
| banking77 | 0.5670 | 0.4460 | 0.2900 | 0.4972 |
| AVERAGE | 0.6695 | 0.6483 | 0.6213 | 0.5173 |
推理速度
每个模型在a6000 GPU上对文本长度为64、256和512个标记,以及标签数量为1、2、4、8、16、32、64和128的示例进行了测试。然后,对不同文本长度的分数进行了平均。
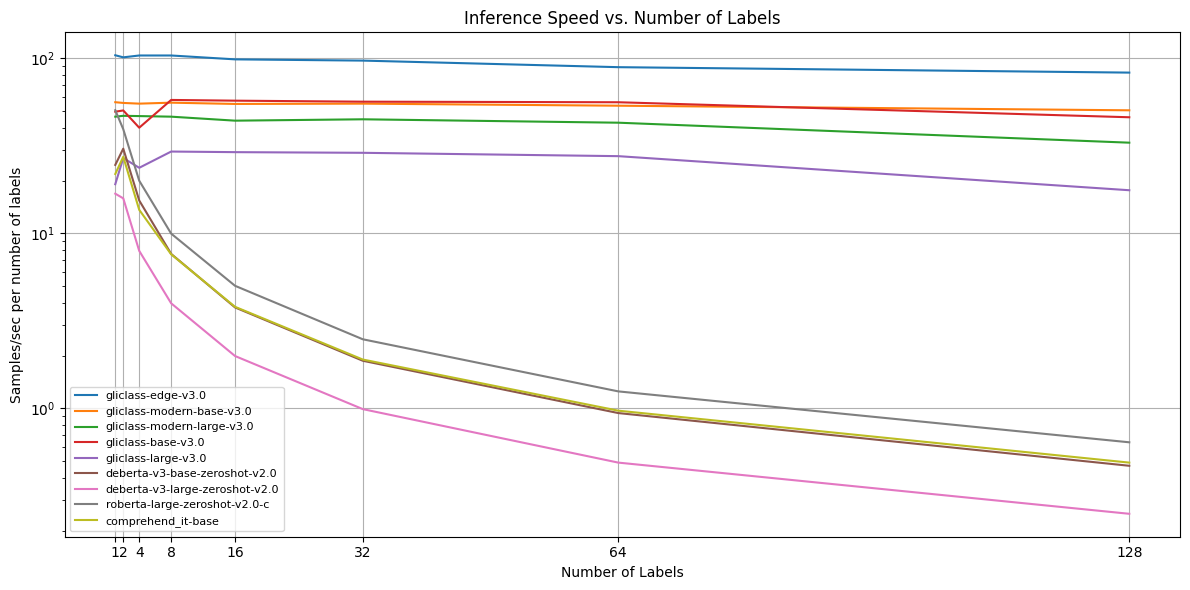
| 模型名称 / 每秒样本数 / m个标签 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| gliclass‑edge‑v3.0 | 103.81 | 101.01 | 103.50 | 103.50 | 98.36 | 96.77 | 88.76 | 82.64 | 97.29 |
| gliclass‑modern‑base‑v3.0 | 56.00 | 55.46 | 54.95 | 55.66 | 54.73 | 54.95 | 53.48 | 50.34 | 54.46 |
| gliclass‑modern‑large‑v3.0 | 46.30 | 46.82 | 46.66 | 46.30 | 43.93 | 44.73 | 42.77 | 32.89 | 43.80 |
| gliclass‑base‑v3.0 | 49.42 | 50.25 | 40.05 | 57.69 | 57.14 | 56.39 | 55.97 | 45.94 | 51.61 |
| gliclass‑large‑v3.0 | 19.05 | 26.86 | 23.64 | 29.27 | 29.04 | 28.79 | 27.55 | 17.60 | 25.22 |
| deberta‑v3‑base‑zeroshot‑v2.0 | 24.55 | 30.40 | 15.38 | 7.62 | 3.77 | 1.87 | 0.94 | 0.47 | 10.63 |
| deberta‑v3‑large‑zeroshot‑v2.0 | 16.82 | 15.82 | 7.93 | 3.98 | 1.99 | 0.99 | 0.49 | 0.25 | 6.03 |
| roberta‑large‑zeroshot‑v2.0‑c | 50.42 | 39.27 | 19.95 | 9.95 | 5.01 | 2.48 | 1.25 | 0.64 | 16.12 |
| comprehend_it‑base | 21.79 | 27.32 | 13.60 | 7.58 | 3.80 | 1.90 | 0.97 | 0.49 | 9.72 |
📄 许可证
本项目采用Apache-2.0许可证。
Gliclass Edge V3.0
Apache-2.0
GLiClass是一款高效的零样本分类器,性能与交叉编码器相当但计算效率更高,适用于多任务场景。
文本分类 Safetensors 其他
Safetensors 其他
Safetensors 其他G
knowledgator
105
4
Gliclass X Base
Apache-2.0
GLiClass 是一个高效的零样本分类器,性能与交叉编码器相当但计算效率更高,支持多语言文本分类任务。
文本分类 Safetensors
SafetensorsG
knowledgator
181
4
Gliclass Modern Base V3.0
Apache-2.0
GLiClass 是一款高效的零样本分类器,受 GLiNER 启发,能在单次前向传播中完成分类任务,兼具交叉编码器性能和更高计算效率。
文本分类 Safetensors 其他
Safetensors 其他G
knowledgator
105
2
Langcache Crossencoder V1 Ms Marco MiniLM L12 V2
Apache-2.0
基于Transformer架构的CrossEncoder模型,在Quora问题对数据集上微调,用于计算文本对得分,适用于语义相似度和语义搜索任务。
文本分类 英语
L
aditeyabaral-redis
281
0
Langcache Crossencoder V1 Ms Marco MiniLM L6 V2
Apache-2.0
这是一个基于Cross Encoder架构的模型,专门用于文本对分类任务,在Quora问题对数据集上微调而来,适用于语义相似性判断和语义搜索场景。
文本分类 英语
L
aditeyabaral-redis
338
0
Koelectra Fine Tunning Emotion
MIT
基于KoELECTRA微调的韩语情感分类模型,能识别愤怒、幸福、焦虑、尴尬、悲伤和心痛六种情感。
文本分类 Transformers 韩语
Transformers 韩语
K
Jinuuuu
441
1
The Teacher V 2
这是一个用于零样本分类任务的transformers模型,可在无需大量标注数据的情况下对文本进行分类。
文本分类 Transformers
T
shiviklabs
172
0
Gender Prediction Model From Text
MIT
该模型基于DeBERTa-v3-large构建,能够根据英文文本内容预测匿名发言者或作者的性别。
文本分类 Transformers 英语
G
fc63
106
1
Qwen3 Reranker 0.6B W4A16 G128
Apache-2.0
Qwen3-Reranker-0.6B的GPTQ量化版本,显存使用优化且精度损失小
文本分类 Transformers
Q
boboliu
151
1
Bert Finetuned Mental Health
Apache-2.0
基于BERT-base-uncased微调的心理健康文本分类模型,可将文本分类为七种心理健康类别。
文本分类 Transformers 英语
B
Elite13
897
2
精选推荐AI模型
Qwen2.5 VL 7B Abliterated Caption It I1 GGUF
Apache-2.0
Qwen2.5-VL-7B-Abliterated-Caption-it的量化版本,支持多语言图像描述任务。
图像生成文本 Transformers 支持多种语言
Q
mradermacher
167
1
Nunchaku Flux.1 Dev Colossus
其他
Colossus Project Flux 的 Nunchaku 量化版本,旨在根据文本提示生成高质量图像。该模型在优化推理效率的同时,将性能损失降至最低。
图像生成 英语
N
nunchaku-tech
235
3
Qwen2.5 VL 7B Abliterated Caption It GGUF
Apache-2.0
这是一个基于Qwen2.5-VL-7B模型的静态量化版本,专注于图像描述生成任务,支持多种语言。
图像生成文本 Transformers 支持多种语言
Q
mradermacher
133
1
Olmocr 7B 0725 FP8
Apache-2.0
olmOCR-7B-0725-FP8是基于Qwen2.5-VL-7B-Instruct模型,使用olmOCR-mix-0225数据集微调后量化为FP8版本的文档OCR模型。
图像生成文本 Transformers 英语
O
allenai
881
3
Lucy 128k GGUF
Apache-2.0
Lucy-128k是基于Qwen3-1.7B开发的专注于代理式网络搜索和轻量级浏览的模型,在移动设备上也能高效运行。
大型语言模型 Transformers 英语
L
Mungert
263
2