%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Controlnet - v1.1 - 图像修复版本
Controlnet v1.1 是一种强大的神经网络结构,可通过添加额外条件来控制扩散模型。此版本的图像修复版本能与 Stable Diffusion 结合使用,为图像生成提供更多的控制和灵活性。
🚀 快速开始
安装依赖
$ pip install diffusers transformers accelerate
运行示例代码
# !pip install transformers accelerate
from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel
from diffusers.utils import load_image
import numpy as np
import torch
init_image = load_image(
"https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy.png"
)
init_image = init_image.resize((512, 512))
generator = torch.Generator(device="cpu").manual_seed(1)
mask_image = load_image(
"https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy_mask.png"
)
mask_image = mask_image.resize((512, 512))
def make_inpaint_condition(image, image_mask):
image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
assert image.shape[0:1] == image_mask.shape[0:1], "image and image_mask must have the same image size"
image[image_mask > 0.5] = -1.0 # set as masked pixel
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return image
control_image = make_inpaint_condition(init_image, mask_image)
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
# generate image
image = pipe(
"a handsome man with ray-ban sunglasses",
num_inference_steps=20,
generator=generator,
eta=1.0,
image=init_image,
mask_image=mask_image,
control_image=control_image,
).images[0]
示例图片



✨ 主要特性
- 额外条件控制:ControlNet 是一种神经网络结构,可通过添加额外条件来控制扩散模型。
- 图像修复功能:此检查点对应于基于图像修复的 ControlNet,可用于图像修复任务。
- 与 Stable Diffusion 结合:可与 Stable Diffusion 结合使用,如 runwayml/stable-diffusion-v1-5。
📦 安装指南
$ pip install diffusers transformers accelerate
💻 使用示例
基础用法
# 上述快速开始中的代码即为基础用法示例
📚 详细文档
模型详情
| 属性 | 详情 |
|---|---|
| 开发者 | Lvmin Zhang, Maneesh Agrawala |
| 模型类型 | 基于扩散的文本到图像生成模型 |
| 语言 | 英文 |
| 许可证 | The CreativeML OpenRAIL M license 是一种 Open RAIL M license,改编自 BigScience 和 the RAIL Initiative 在负责任的 AI 许可领域的联合工作。另见 关于 BLOOM Open RAIL 许可证的文章,本许可证基于此。 |
| 更多信息资源 | GitHub 仓库,论文 |
模型介绍
Controlnet 由 Lvmin Zhang 和 Maneesh Agrawala 在 Adding Conditional Control to Text-to-Image Diffusion Models 中提出。
论文摘要如下: 我们提出了一种神经网络结构 ControlNet,用于控制预训练的大型扩散模型以支持额外的输入条件。ControlNet 以端到端的方式学习特定任务的条件,即使训练数据集较小(< 50k),学习过程也很稳健。此外,训练一个 ControlNet 与微调一个扩散模型一样快,并且该模型可以在个人设备上进行训练。或者,如果有强大的计算集群,该模型可以扩展到大量(数百万到数十亿)的数据。我们报告称,像 Stable Diffusion 这样的大型扩散模型可以通过 ControlNets 进行增强,以实现诸如边缘图、分割图、关键点等条件输入。这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用。
其他发布的检查点 v1-1
作者发布了 14 个不同的检查点,每个检查点都在 Stable Diffusion v1-5 上针对不同类型的条件进行了训练:
| 模型名称 | 控制图像概述 | 条件图像 | 控制图像示例 | 生成图像示例 |
|---|---|---|---|---|
| lllyasviel/control_v11p_sd15_canny |
使用 Canny 边缘检测进行训练 | 黑色背景上带有白色边缘的单色图像。 |  |
 |
| lllyasviel/control_v11e_sd15_ip2p |
使用像素到像素指令进行训练 | 无条件。 |  |
 |
| lllyasviel/control_v11p_sd15_inpaint |
使用图像修复进行训练 | 无条件。 |  |
 |
| lllyasviel/control_v11p_sd15_mlsd |
使用多级线段检测进行训练 | 带有注释线段的图像。 |  |
 |
| lllyasviel/control_v11f1p_sd15_depth |
使用深度估计进行训练 | 带有深度信息的图像,通常表示为灰度图像。 |  |
 |
| lllyasviel/control_v11p_sd15_normalbae |
使用表面法线估计进行训练 | 带有表面法线信息的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_seg |
使用图像分割进行训练 | 带有分割区域的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_lineart |
使用线稿生成进行训练 | 带有线稿的图像,通常是白色背景上的黑色线条。 |  |
 |
| lllyasviel/control_v11p_sd15s2_lineart_anime |
使用动漫线稿生成进行训练 | 带有动漫风格线稿的图像。 |  |
 |
| lllyasviel/control_v11p_sd15_openpose |
使用人体姿态估计进行训练 | 带有人体姿态的图像,通常表示为一组关键点或骨架。 | 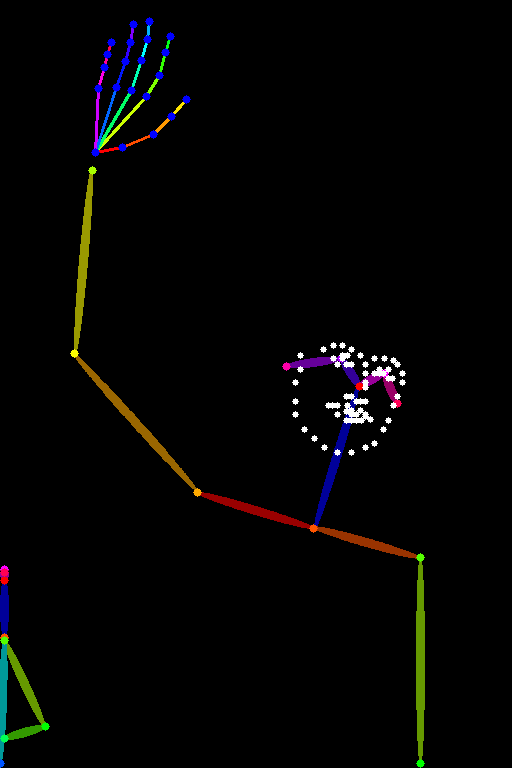 |
 |
| lllyasviel/control_v11p_sd15_scribble |
使用基于涂鸦的图像生成进行训练 | 带有涂鸦的图像,通常是随机或用户绘制的笔触。 |  |
 |
| lllyasviel/control_v11p_sd15_softedge |
使用软边缘图像生成进行训练 | 带有软边缘的图像,通常用于创建更具绘画感或艺术效果。 |  |
 |
| lllyasviel/control_v11e_sd15_shuffle |
使用图像打乱进行训练 | 带有打乱的补丁或区域的图像。 |  |
 |
| lllyasviel/control_v11f1e_sd15_tile |
使用图像平铺进行训练 | 模糊图像或图像的一部分。 |  |
 |
更多信息
如需更多信息,请查看 Diffusers ControlNet 博客文章 和 官方文档。
🔧 技术细节
ControlNet 以端到端的方式学习特定任务的条件,即使训练数据集较小(< 50k),学习过程也很稳健。此外,训练一个 ControlNet 与微调一个扩散模型一样快,并且该模型可以在个人设备上进行训练。或者,如果有强大的计算集群,该模型可以扩展到大量(数百万到数十亿)的数据。
📄 许可证
本模型使用 The CreativeML OpenRAIL M license,这是一种 Open RAIL M license,改编自 BigScience 和 the RAIL Initiative 在负责任的 AI 许可领域的联合工作。另见 关于 BLOOM Open RAIL 许可证的文章,本许可证基于此。
引用格式
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}