%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
T2iadapter Seg Sd14v1
T2I适配器是为稳定扩散模型提供额外条件控制的网络架构,本检查点专为稳定扩散1.4版本提供语义分割条件控制。
下载量 21
发布时间 : 7/14/2023
模型简介
该模型通过适配器架构为稳定扩散模型添加语义分割条件控制能力,能够根据输入的分割图生成符合语义结构的图像。
模型特点
语义分割控制
能够根据输入的语义分割图精确控制生成图像的布局和结构
轻量级适配器
采用轻量级适配器架构,不改变原有稳定扩散模型参数
高兼容性
专为稳定扩散1.4版本设计,可与基础模型无缝配合使用
模型能力
语义分割条件图像生成
图像布局精确控制
文本到图像转换
使用案例
创意设计
概念艺术创作
设计师可以通过绘制语义分割草图快速生成概念艺术图像
快速可视化设计概念,提高创作效率
建筑可视化
建筑方案展示
根据建筑平面分割图生成逼真的建筑外观效果
快速生成多种风格建筑效果图
🚀 T2I Adapter - Segment
T2I Adapter是一个为Stable Diffusion提供额外条件控制的网络。每个T2I检查点以不同类型的条件作为输入,并与特定的基础Stable Diffusion检查点一起使用。此检查点为Stable Diffusion 1.4检查点提供语义分割条件控制。
🚀 快速开始
依赖安装
pip install diffusers transformers
运行代码
import torch
from PIL import Image
import numpy as np
from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
from diffusers import (
T2IAdapter,
StableDiffusionAdapterPipeline
)
ada_palette = np.asarray([
[0, 0, 0],
[120, 120, 120],
[180, 120, 120],
[6, 230, 230],
[80, 50, 50],
[4, 200, 3],
[120, 120, 80],
[140, 140, 140],
[204, 5, 255],
[230, 230, 230],
[4, 250, 7],
[224, 5, 255],
[235, 255, 7],
[150, 5, 61],
[120, 120, 70],
[8, 255, 51],
[255, 6, 82],
[143, 255, 140],
[204, 255, 4],
[255, 51, 7],
[204, 70, 3],
[0, 102, 200],
[61, 230, 250],
[255, 6, 51],
[11, 102, 255],
[255, 7, 71],
[255, 9, 224],
[9, 7, 230],
[220, 220, 220],
[255, 9, 92],
[112, 9, 255],
[8, 255, 214],
[7, 255, 224],
[255, 184, 6],
[10, 255, 71],
[255, 41, 10],
[7, 255, 255],
[224, 255, 8],
[102, 8, 255],
[255, 61, 6],
[255, 194, 7],
[255, 122, 8],
[0, 255, 20],
[255, 8, 41],
[255, 5, 153],
[6, 51, 255],
[235, 12, 255],
[160, 150, 20],
[0, 163, 255],
[140, 140, 140],
[250, 10, 15],
[20, 255, 0],
[31, 255, 0],
[255, 31, 0],
[255, 224, 0],
[153, 255, 0],
[0, 0, 255],
[255, 71, 0],
[0, 235, 255],
[0, 173, 255],
[31, 0, 255],
[11, 200, 200],
[255, 82, 0],
[0, 255, 245],
[0, 61, 255],
[0, 255, 112],
[0, 255, 133],
[255, 0, 0],
[255, 163, 0],
[255, 102, 0],
[194, 255, 0],
[0, 143, 255],
[51, 255, 0],
[0, 82, 255],
[0, 255, 41],
[0, 255, 173],
[10, 0, 255],
[173, 255, 0],
[0, 255, 153],
[255, 92, 0],
[255, 0, 255],
[255, 0, 245],
[255, 0, 102],
[255, 173, 0],
[255, 0, 20],
[255, 184, 184],
[0, 31, 255],
[0, 255, 61],
[0, 71, 255],
[255, 0, 204],
[0, 255, 194],
[0, 255, 82],
[0, 10, 255],
[0, 112, 255],
[51, 0, 255],
[0, 194, 255],
[0, 122, 255],
[0, 255, 163],
[255, 153, 0],
[0, 255, 10],
[255, 112, 0],
[143, 255, 0],
[82, 0, 255],
[163, 255, 0],
[255, 235, 0],
[8, 184, 170],
[133, 0, 255],
[0, 255, 92],
[184, 0, 255],
[255, 0, 31],
[0, 184, 255],
[0, 214, 255],
[255, 0, 112],
[92, 255, 0],
[0, 224, 255],
[112, 224, 255],
[70, 184, 160],
[163, 0, 255],
[153, 0, 255],
[71, 255, 0],
[255, 0, 163],
[255, 204, 0],
[255, 0, 143],
[0, 255, 235],
[133, 255, 0],
[255, 0, 235],
[245, 0, 255],
[255, 0, 122],
[255, 245, 0],
[10, 190, 212],
[214, 255, 0],
[0, 204, 255],
[20, 0, 255],
[255, 255, 0],
[0, 153, 255],
[0, 41, 255],
[0, 255, 204],
[41, 0, 255],
[41, 255, 0],
[173, 0, 255],
[0, 245, 255],
[71, 0, 255],
[122, 0, 255],
[0, 255, 184],
[0, 92, 255],
[184, 255, 0],
[0, 133, 255],
[255, 214, 0],
[25, 194, 194],
[102, 255, 0],
[92, 0, 255],
])
image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small")
image_segmentor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small")
checkpoint = "lllyasviel/control_v11p_sd15_seg"
image = Image.open('./images/seg_input.jpeg')
pixel_values = image_processor(image, return_tensors="pt").pixel_values
with torch.no_grad():
outputs = image_segmentor(pixel_values)
seg = image_processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3
for label, color in enumerate(ada_palette):
color_seg[seg == label, :] = color
color_seg = color_seg.astype(np.uint8)
control_image = Image.fromarray(color_seg)
control_image.save("./images/segment_image.png")
adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_seg_sd14v1", torch_dtype=torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", adapter=adapter, safety_checker=None, torch_dtype=torch.float16, variant="fp16"
)
pipe.to('cuda')
generator = torch.Generator().manual_seed(0)
sketch_image_out = pipe(prompt="motorcycles driving", image=control_image, generator=generator).images[0]
sketch_image_out.save('./images/seg_image_out.png')



✨ 主要特性
- 为Stable Diffusion提供额外的条件控制,增强图像生成的可控性。
- 不同的检查点支持不同类型的条件输入,适用于多样化的图像生成场景。
📚 详细文档
模型详情
| 属性 | 详情 |
|---|---|
| 开发者 | 《T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models》 |
| 模型类型 | 基于扩散模型的文本到图像生成模型 |
| 语言 | 英文 |
| 许可证 | Apache 2.0 |
| 更多信息资源 | GitHub仓库,论文 |
| 引用方式 | @misc{ |
检查点
| 模型名称 | 控制图像概述 | 控制图像示例 | 生成图像示例 |
|---|---|---|---|
| TencentARC/t2iadapter_color_sd14v1 使用空间颜色调色板训练 |
带有8x8颜色调色板的图像。 |  |
 |
| TencentARC/t2iadapter_canny_sd14v1 使用Canny边缘检测训练 |
黑色背景上带有白色边缘的单色图像。 |  |
 |
| TencentARC/t2iadapter_sketch_sd14v1 使用PidiNet边缘检测训练 |
黑色背景上带有白色轮廓的手绘单色图像。 |  |
 |
| TencentARC/t2iadapter_depth_sd14v1 使用Midas深度估计训练 |
黑色代表深区域,白色代表浅区域的灰度图像。 |  |
 |
| TencentARC/t2iadapter_openpose_sd14v1 使用OpenPose骨骼图像训练 |
OpenPose骨骼图像。 | 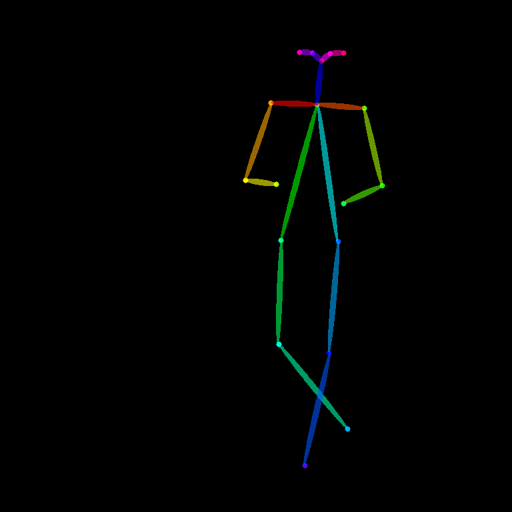 |
 |
| TencentARC/t2iadapter_keypose_sd14v1 使用mmpose骨架图像训练 |
mmpose骨架图像。 |  |
 |
| TencentARC/t2iadapter_seg_sd14v1 使用语义分割训练 |
自定义分割协议图像。 |  |
 |
| TencentARC/t2iadapter_canny_sd15v2 | |||
| TencentARC/t2iadapter_depth_sd15v2 | |||
| TencentARC/t2iadapter_sketch_sd15v2 | |||
| TencentARC/t2iadapter_zoedepth_sd15v1 |
💻 使用示例
基础用法
上述快速开始部分的代码展示了如何使用T2I Adapter进行语义分割条件下的图像生成,包括依赖安装、模型加载、图像分割处理和图像生成等步骤。
高级用法
你可以根据具体需求调整代码中的参数,如修改提示词prompt、随机种子seed等,以生成不同风格和内容的图像。同时,尝试使用不同的检查点和条件输入,探索更多的图像生成可能性。
📄 许可证
本项目采用Apache 2.0许可证。详细信息请参考许可证文件。
Stable Diffusion V1 5
Openrail
稳定扩散是一种潜在的文本到图像扩散模型,能够根据任何文本输入生成逼真的图像。
图像生成
S
stable-diffusion-v1-5
3.7M
518
Stable Diffusion Inpainting
Openrail
基于稳定扩散的文本到图像生成模型,具备图像修复能力
图像生成
S
stable-diffusion-v1-5
3.3M
56
Stable Diffusion Xl Base 1.0
SDXL 1.0是基于扩散的文本生成图像模型,采用专家集成的潜在扩散流程,支持高分辨率图像生成
图像生成
S
stabilityai
2.4M
6,545
Stable Diffusion V1 4
Openrail
稳定扩散是一种潜在文本到图像扩散模型,能够根据任意文本输入生成逼真图像。
图像生成
S
CompVis
1.7M
6,778
Stable Diffusion Xl Refiner 1.0
SD-XL 1.0优化器模型是Stability AI开发的图像生成模型,专为提升SDXL基础模型生成的图像质量而设计,特别擅长最终去噪步骤处理。
图像生成
S
stabilityai
1.1M
1,882
Stable Diffusion 2 1
基于扩散的文本生成图像模型,支持通过文本提示生成和修改图像
图像生成
S
stabilityai
948.75k
3,966
Stable Diffusion Xl 1.0 Inpainting 0.1
基于Stable Diffusion XL的潜在文本到图像扩散模型,具备通过遮罩进行图像修复的功能
图像生成
S
diffusers
673.14k
334
Stable Diffusion 2 Base
基于扩散的文生图模型,可根据文本提示生成高质量图像
图像生成
S
stabilityai
613.60k
349
Playground V2.5 1024px Aesthetic
其他
开源文生图模型,能生成1024x1024分辨率及多种纵横比的美学图像,在美学质量上处于开源领域领先地位。
图像生成
P
playgroundai
554.94k
723
Sd Turbo
SD-Turbo是一款高速文本生成图像模型,仅需单次网络推理即可根据文本提示生成逼真图像。该模型作为研究原型发布,旨在探索小型蒸馏文本生成图像模型。
图像生成
S
stabilityai
502.82k
380
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98