%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
Vintern 1B V3 5
模型简介
该模型是Vintern系列的最新版本,在保持英语能力的同时显著提升了越南语性能,擅长处理发票、法律文本、手写体和表格等越南特色文档。
模型特点
越南语文本处理顶级质量
是同级别(10亿参数)中理解和处理越南语文档的最佳模型之一
更优的提取与理解能力
擅长处理发票、法律文本、手写体和表格等复杂文档
提升的提示理解能力
相比v2版本,能理解更复杂的提示,使用更便捷
平价硬件运行
可在配备T4 GPU的Google Colab上运行,无需昂贵设备
易于微调
只需少量工作即可针对特定任务定制模型
模型能力
越南语文档理解
文本识别
OCR
表格处理
多语言支持
图像文本理解
使用案例
文档处理
发票信息提取
从越南语发票中提取关键信息
准确识别发票中的金额、日期等信息
法律文本分析
解析越南语法律文档
理解法律条款和关键内容
教育
手写体识别
识别越南语手写笔记
准确转换手写内容为数字文本
🚀 Vintern-1B-v3.5 ❄️
我们推出了 Vintern-1B-v3.5,这是Vintern系列的最新版本,在所有评估基准上都比v2有显著改进。该模型基于 InternVL2.5-1B 进行微调,由于InternVL 2.5 [1]团队在微调过程中使用了 Viet-ShareGPT-4o-Text-VQA 数据,因此它在越南语 🇻🇳 任务上表现出色。
为了在保持现有英文数据集良好性能的同时,进一步提升其在越南语方面的表现,Vintern-1B-v3.5 使用了大量越南语特定数据进行微调。这使得该模型在文本识别、OCR以及理解越南语特定文档方面表现异常强大。

✨ 主要特性
-
越南语文本处理的顶级质量 Vintern-1B-v3.5是同类(10亿参数)模型中理解和处理越南语文档的最佳模型之一。
-
更出色的信息提取和理解能力 该模型擅长处理发票、法律文本、手写内容和表格。
-
改进的提示理解能力 与v2相比,它能够理解更复杂的提示,使用起来更加便捷。
-
可在经济实惠的硬件上运行 你可以在配备T4 GPU的Google Colab上运行该模型,无需昂贵设备即可轻松使用。
-
易于微调 该模型可以轻松针对特定任务进行定制。
📈 基准测试
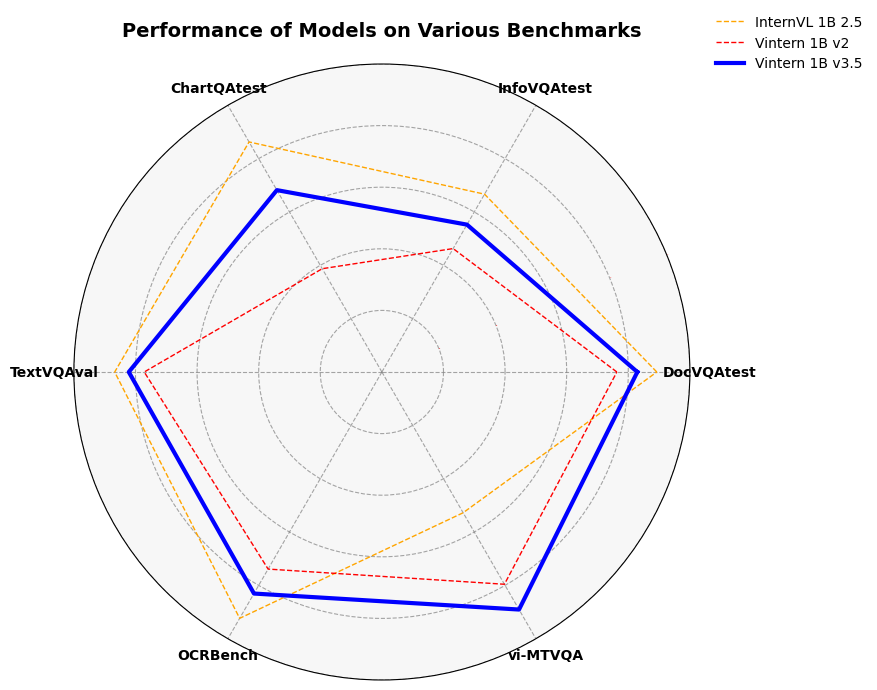
| 基准测试 | InternVL2_5 1B | Vintern-1B-v2 | Vintern-1B-v3.5 |
|---|---|---|---|
| vi-MTVQA | 24.8 | 37.4 | 41.9 |
| DocVQAtest | 84.8 | 72.5 | 78.8 |
| InfoVQAtest | 56.0 | 38.9 | 46.4 |
| TextVQAval | 72.0 | 64.0 | 68.2 |
| ChartQAtest | 75.9 | 34.1 | 65.7 |
| OCRBench | 785 | 628 | 706 |
💻 使用示例
基础用法
import numpy as np
import torch
import torchvision.transforms as T
# from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
model = AutoModel.from_pretrained(
"5CD-AI/Vintern-1B-v3_5",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
use_flash_attn=False,
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained("5CD-AI/Vintern-1B-v3_5", trust_remote_code=True, use_fast=False)
test_image = 'test-image.jpg'
pixel_values = load_image(test_image, max_num=6).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens= 1024, do_sample=False, num_beams = 3, repetition_penalty=2.5)
question = '<image>\nTrích xuất thông tin chính trong ảnh và trả về dạng markdown.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
#question = "Câu hỏi khác ......"
#response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
#print(f'User: {question}\nAssistant: {response}')
高级用法
这里提供了一段代码片段,展示如何加载分词器和模型以及如何生成内容。要使用该模型进行推理,请按照我们的Colab推理笔记本中概述的步骤操作。
![]()
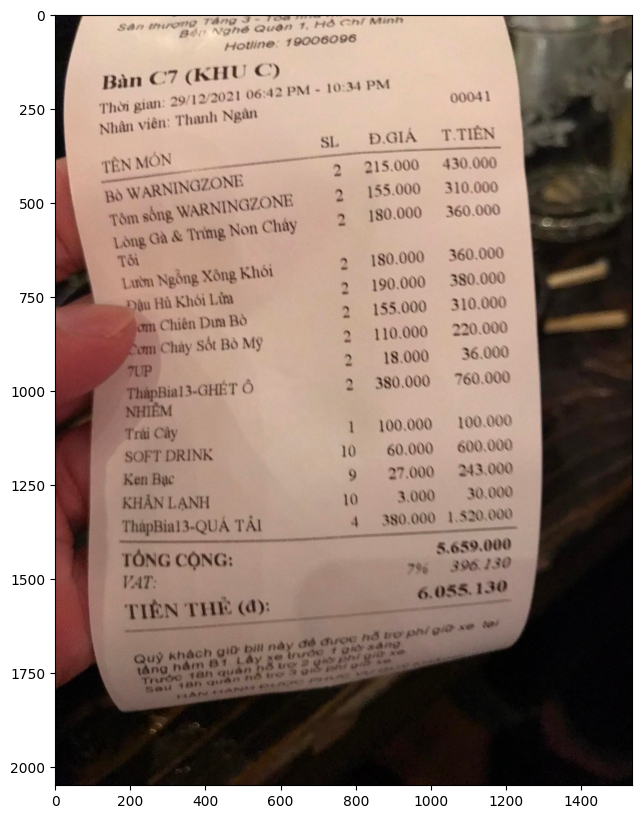
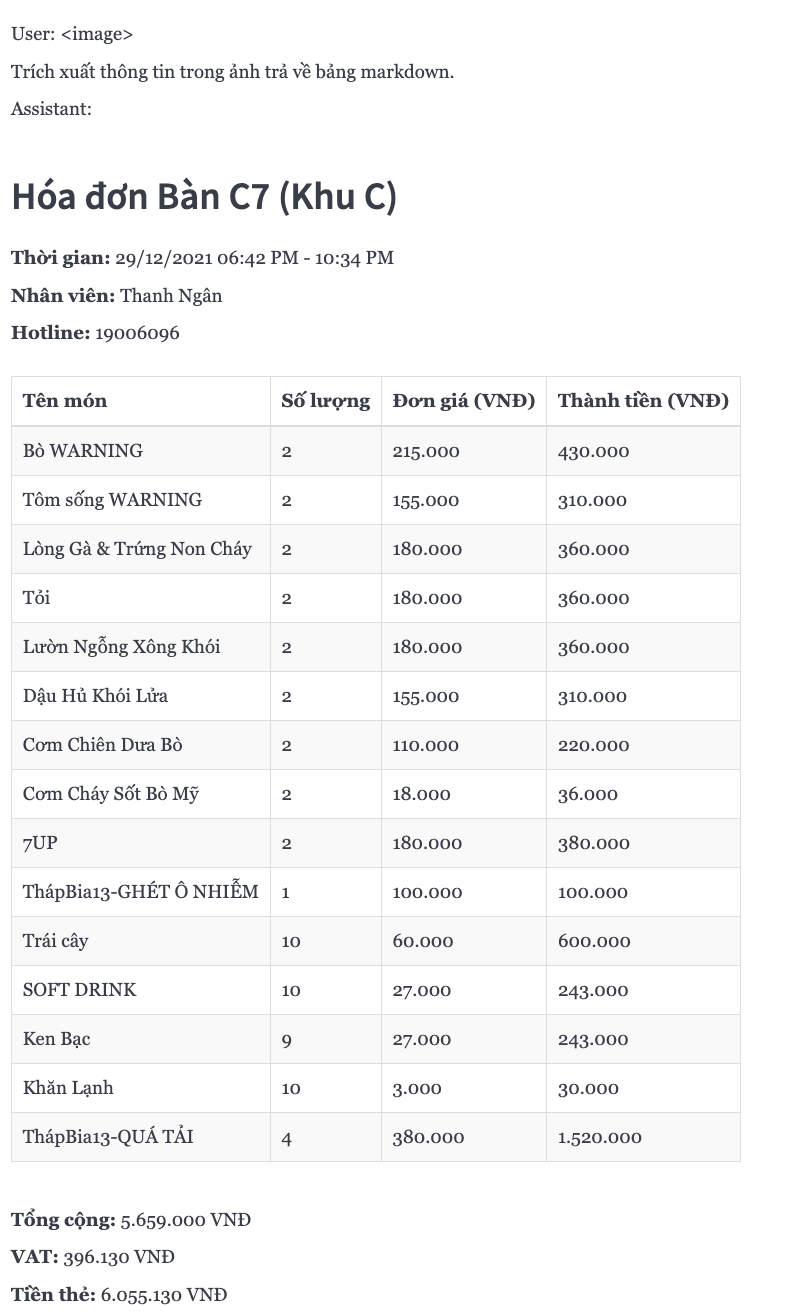
📚 详细文档
示例图片





📄 许可证
本项目采用MIT许可证。
📖 引用
@misc{doan2024vintern1befficientmultimodallarge,
title={Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese},
author={Khang T. Doan and Bao G. Huynh and Dung T. Hoang and Thuc D. Pham and Nhat H. Pham and Quan T. M. Nguyen and Bang Q. Vo and Suong N. Hoang},
year={2024},
eprint={2408.12480},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.12480},
}
🔗 参考
[1] Z. Chen et al., ‘Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling’, arXiv preprint arXiv:2412. 05271, 2024.
📋 模型信息
| 属性 | 详情 |
|---|---|
| 库名称 | transformers |
| 支持语言 | 越南语、英语、中文 |
| 基础模型 | OpenGVLab/InternVL2_5-1B |
| 任务类型 | 图像文本转文本 |
Clip Vit Large Patch14
CLIP是由OpenAI开发的视觉-语言模型,通过对比学习将图像和文本映射到共享的嵌入空间,支持零样本图像分类
图像生成文本
C
openai
44.7M
1,710
Clip Vit Base Patch32
CLIP是由OpenAI开发的多模态模型,能够理解图像和文本之间的关系,支持零样本图像分类任务。
图像生成文本
C
openai
14.0M
666
Siglip So400m Patch14 384
Apache-2.0
SigLIP是基于WebLi数据集预训练的视觉语言模型,采用改进的sigmoid损失函数,优化了图像-文本匹配任务。
图像生成文本 Transformers
Transformers
S
google
6.1M
526
Clip Vit Base Patch16
CLIP是由OpenAI开发的多模态模型,通过对比学习将图像和文本映射到共享的嵌入空间,实现零样本图像分类能力。
图像生成文本
C
openai
4.6M
119
Blip Image Captioning Base
Bsd-3-clause
BLIP是一个先进的视觉-语言预训练模型,擅长图像描述生成任务,支持条件式和非条件式文本生成。
图像生成文本 Transformers
B
Salesforce
2.8M
688
Blip Image Captioning Large
Bsd-3-clause
BLIP是一个统一的视觉-语言预训练框架,擅长图像描述生成任务,支持条件式和无条件式图像描述生成。
图像生成文本 Transformers
B
Salesforce
2.5M
1,312
Openvla 7b
MIT
OpenVLA 7B是一个基于Open X-Embodiment数据集训练的开源视觉-语言-动作模型,能够根据语言指令和摄像头图像生成机器人动作。
图像生成文本 Transformers 英语
O
openvla
1.7M
108
Llava V1.5 7b
LLaVA 是一款开源多模态聊天机器人,基于 LLaMA/Vicuna 微调,支持图文交互。
图像生成文本 Transformers
L
liuhaotian
1.4M
448
Vit Gpt2 Image Captioning
Apache-2.0
这是一个基于ViT和GPT2架构的图像描述生成模型,能够为输入图像生成自然语言描述。
图像生成文本 Transformers
V
nlpconnect
939.88k
887
Blip2 Opt 2.7b
MIT
BLIP-2是一个视觉语言模型,结合了图像编码器和大型语言模型,用于图像到文本的生成任务。
图像生成文本 Transformers 英语
B
Salesforce
867.78k
359
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98