🚀 jina-embeddings-v2-base-de
jina-embeddings-v2-base-de 是一款由 Jina AI 訓練的德英雙語文本嵌入模型,支持長達 8192 的序列長度。該模型在單語言和跨語言應用中表現出色,能無偏處理德英混合輸入。
🚀 快速開始
使用 jina-embeddings-v2-base-de 最簡單的方法是使用 Jina AI 的 Embedding API。
✨ 主要特性
- 雙語支持:支持德語和英語兩種語言,能無偏處理德英混合輸入。
- 長序列處理:支持長達 8192 的序列長度。
- 高性能:基於 BERT 架構(JinaBERT),採用對稱雙向的 ALiBi 變體,在單語言和跨語言應用中表現出色。
此外,還提供以下嵌入模型:
📦 安裝指南
使用前需安裝 transformers 庫:
!pip install transformers
若使用 sentence-transformers,需安裝並更新:
!pip install -U sentence-transformers
💻 使用示例
基礎用法
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['How is the weather today?', 'What is the current weather like today?']
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-de')
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True, torch_dtype=torch.bfloat16)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
高級用法
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True, torch_dtype=torch.bfloat16)
embeddings = model.encode(['How is the weather today?', 'Wie ist das Wetter heute?'])
print(cos_sim(embeddings[0], embeddings[1]))
處理短序列
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
使用 sentence-transformers
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-de",
trust_remote_code=True
)
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'Wie ist das Wetter heute?'
])
print(cos_sim(embeddings[0], embeddings[1]))
📚 詳細文檔
數據與參數
數據和訓練細節詳見此 技術報告。
替代使用方式
- 託管 SaaS:在 Jina AI 的 Embedding API 上獲取免費密鑰開始使用。
- 私有高性能部署:從模型套件中選擇模型,並在 AWS Sagemaker 上進行部署。
基準測試結果
在 MTEB 基準測試 上對雙語模型進行了所有可用的德語和英語評估任務的評估。此外,還在額外的德語評估任務中與其他幾個德語、英語和多語言模型進行了對比評估:

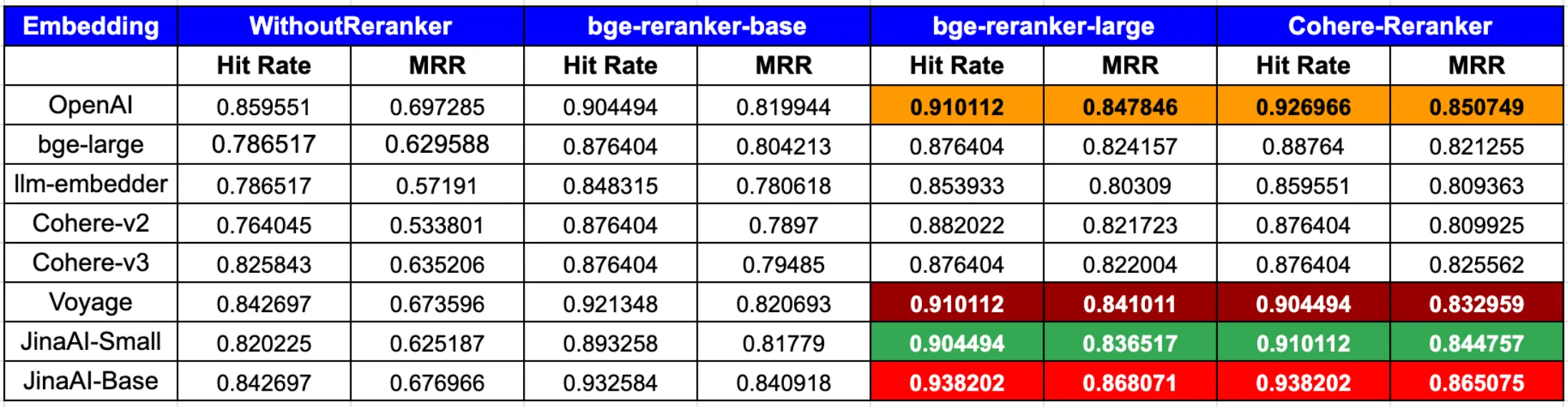
在 RAG 中使用 Jina Embeddings
根據 LLamaIndex 最新博客文章:
綜上所述,為了在命中率和 MRR 方面達到最佳性能,將 OpenAI 或 JinaAI-Base 嵌入與 CohereRerank/bge-reranker-large 重排器結合使用效果最佳。
🔧 技術細節
為什麼使用平均池化?
mean pooling 會獲取模型輸出的所有詞元嵌入,並在句子/段落級別對其進行平均。實踐證明,這是生成高質量句子嵌入最有效的方法。提供了一個 encode 函數來處理此操作。
若不使用默認的 encode 函數,可參考以下代碼:
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['How is the weather today?', 'What is the current weather like today?']
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-de')
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True, torch_dtype=torch.bfloat16)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
📄 許可證
本項目採用 Apache 2.0 許可證。
聯繫我們
加入我們的 Discord 社區,與其他社區成員交流想法。
引用
如果您在研究中發現 Jina Embeddings 很有用,請引用以下論文:
@article{mohr2024multi,
title={Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings},
author={Mohr, Isabelle and Krimmel, Markus and Sturua, Saba and Akram, Mohammad Kalim and Koukounas, Andreas and G{\"u}nther, Michael and Mastrapas, Georgios and Ravishankar, Vinit and Mart{\'\i}nez, Joan Fontanals and Wang, Feng and others},
journal={arXiv preprint arXiv:2402.17016},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言