🚀 SDXL-controlnet: OpenPose (v2)
這是一個基於StableDiffusionXL的ControlNet模型,使用OpenPose (v2)條件進行訓練,可用於文本到圖像的生成。
🚀 快速開始
此項目是 thibaud/controlnet-openpose-sdxl-1.0 的副本,允許通過 diffusers 庫直接使用其 safetensors 版本。
✨ 主要特性
- 基於
stabilityai/stable-diffusion-xl-base-1.0 訓練,使用OpenPose (v2) 條件。
- 可通過
diffusers 庫方便地集成和使用。
- 提供了訓練腳本和相關參數說明。
📦 安裝指南
首先,安裝所有必要的庫:
pip install -q controlnet_aux transformers accelerate
pip install -q git+https://github.com/huggingface/diffusers
💻 使用示例
基礎用法
現在,我們可以讓達斯·維達跳舞啦:
from diffusers import AutoencoderKL, StableDiffusionXLControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(image)
controlnet = ControlNetModel.from_pretrained("dimitribarbot/controlnet-openpose-sdxl-1.0-safetensors", torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
prompt = "Darth vader dancing in a desert, high quality"
negative_prompt = "low quality, bad quality"
images = pipe(
prompt,
negative_prompt=negative_prompt,
num_inference_steps=25,
num_images_per_prompt=4,
image=openpose_image.resize((1024, 1024)),
generator=torch.manual_seed(97),
).images
images[0]
以下是一些生成的示例:

示例圖片
提示詞:a ballerina, romantic sunset, 4k photo
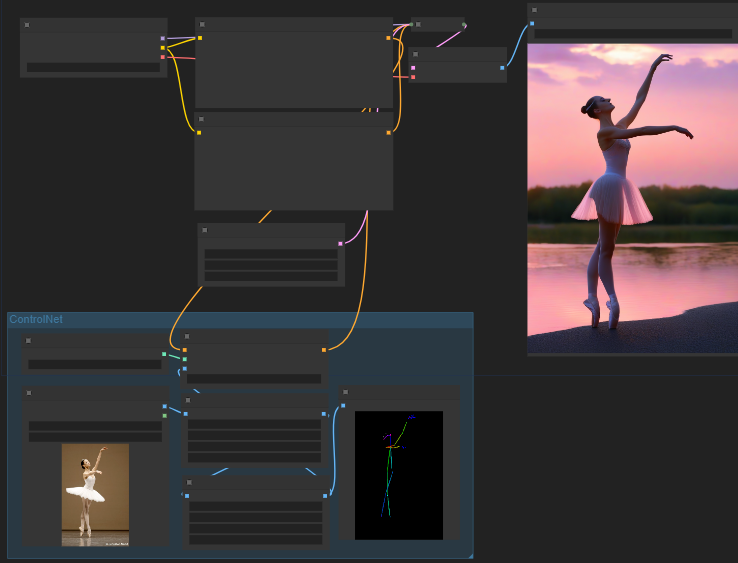
Comfy工作流
 (圖片來自ComfyUI,你可以將其拖放到Comfy中作為工作流使用)
(圖片來自ComfyUI,你可以將其拖放到Comfy中作為工作流使用)
🔧 技術細節
訓練
使用HF🤗 的訓練腳本 點擊此處查看。
訓練數據
此檢查點首先在調整為最大最小尺寸為768的laion 6a上訓練了15,000步。
計算資源
一臺1xA100機器 (非常感謝HF🤗 提供計算資源!)
批量大小
數據並行,單GPU批量大小為2,梯度累積為8。
超參數
恆定學習率為8e-5
混合精度
fp16
📄 許可證
許可證:參考OpenPose的許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言