%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 OpenReasoning-Nemotron-7B 概要
OpenReasoning-Nemotron-7Bは、大規模言語モデル(LLM)で、Qwen2.5-7B-Instruct(参照モデル)をベースにした派生モデルです。数学、コード、科学の問題解決を行うために追加学習された推論モデルで、最大64Kの出力トークンで評価されています。OpenReasoningモデルには、1.5B、7B、14B、32Bのサイズが用意されています。
このモデルは、商用・非商用の研究用途に使用可能です。
ライセンス/使用条件
支配規定:上記のモデルの使用は、Creative Commons Attribution 4.0 International License (CC-BY-4.0)に基づきます。追加情報:Apache 2.0 License
推論ベンチマークでのスコア
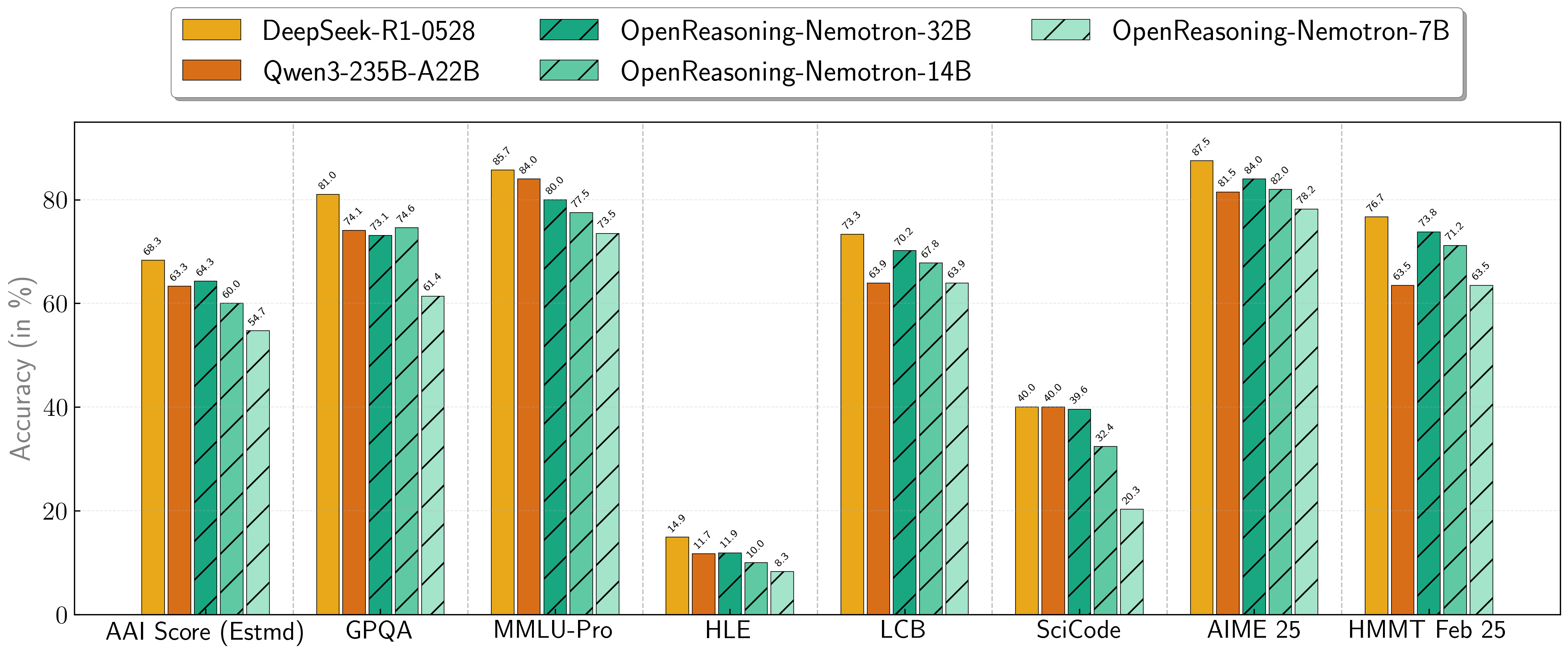
当社のモデルは、一連の困難な推論ベンチマークで卓越した性能を発揮しています。7B、14B、32Bのモデルは、それぞれのサイズクラスで常に新しい最先端記録を樹立しています。
| モデル | 人工分析指数* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* これは人工分析知能指数の当社の推定値であり、公式のスコアではありません。 * LiveCodeBenchバージョン6、日付範囲2408 - 2505。
複数エージェントの作業の組み合わせ
OpenReasoning-Nemotronモデルは、複数の並列生成を開始し、生成的解選択(GenSelect)を介してそれらを組み合わせる「ヘビー」モードで使用できます。この「スキル」を追加するために、元のGenSelect学習パイプラインに従いますが、選択要約での学習は行わず、代わりにDeepSeek R1 0528 671Bの完全な推論トレースを使用します。数学問題の最良の解を選択するようにモデルを学習させるだけですが、驚くべきことに、この機能がコードと科学の質問にも直接一般化されることがわかりました!この「ヘビー」GenSelect推論モードでは、OpenReasoning-Nemotron-32Bモデルが数学とコーディングのベンチマークでO3(High)を上回っています。
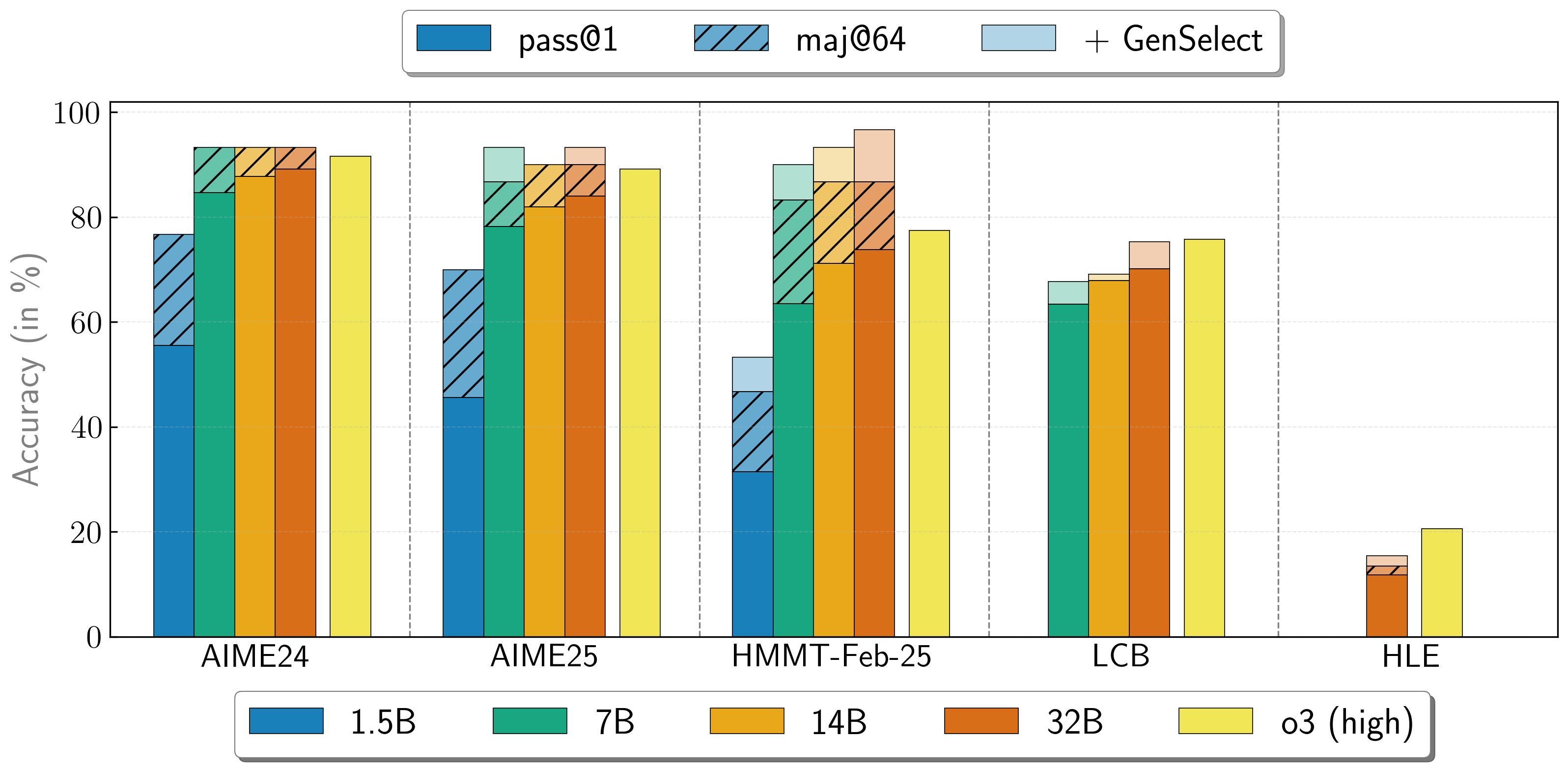
| モデル | Pass@1 (Avg@64) | Majority@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408 - 2505 | 63.4 | n/a | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408 - 2505 | 67.9 | n/a | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408 - 2505 | 70.2 | n/a | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
モデルの使用方法
コーディング問題に対する推論を実行するには、以下のコードを使用します。
import transformers
import torch
model_id = "nvidia/OpenReasoning-Nemotron-7B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# コード生成プロンプト
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
{user} """
数学生成プロンプト
prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \boxed{}.
{user}
"""
科学生成プロンプト
You can refer to prompts here -
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [ { "role": "user", "content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")}, ] outputs = pipeline( messages, max_new_tokens=64000, ) print(outputs[0]["generated_text"][-1]['content'])
## 引用
もしこのデータが役に立った場合は、以下を引用してください。
@article{ahmad2025opencodereasoning, title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}, author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg}, year={2025}, eprint={2504.01943}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2504.01943}, }
@misc{ahmad2025opencodereasoningiisimpletesttime, title={OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}, author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg}, year={2025}, eprint={2507.09075}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2507.09075}, }
@misc{moshkov2025aimo2winningsolutionbuilding, title={AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}, author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman}, year={2025}, eprint={2504.16891}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2504.16891}, }
## 追加情報
### 展開地域
グローバル
### 使用ケース
このモデルは、競技的な数学、コード、科学の問題に取り組む開発者や研究者を対象としています。ベンチマークで高いスコアを達成するために、教師あり微調整のみで学習されています。
### リリース日
Huggingface [2025年7月16日]、https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B/ より
## 参照
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
## モデルアーキテクチャ
アーキテクチャタイプ:Dense decoder-only Transformerモデル
ネットワークアーキテクチャ:Qwen-7B-Instruct
このモデルはQwen2.5-7B-Instructをベースに開発され、7Bのモデルパラメータを持っています。
OpenReasoning-Nemotron-1.5BはQwen2.5-1.5B-Instructをベースに開発され、1.5Bのモデルパラメータを持っています。
OpenReasoning-Nemotron-7BはQwen2.5-7B-Instructをベースに開発され、7Bのモデルパラメータを持っています。
OpenReasoning-Nemotron-14BはQwen2.5-14B-Instructをベースに開発され、14Bのモデルパラメータを持っています。
OpenReasoning-Nemotron-32BはQwen2.5-32B-Instructをベースに開発され、32Bのモデルパラメータを持っています。
## 入力
**入力タイプ**:テキスト
**入力形式**:文字列
**入力パラメータ**:一次元(1D)
**入力に関連するその他の特性**:最大64,000の出力トークンで学習されています。
## 出力
**出力タイプ**:テキスト
**出力形式**:文字列
**出力パラメータ**:一次元(1D)
**出力に関連するその他の特性**:最大64,000の出力トークンで学習されています。
当社のAIモデルは、NVIDIA GPUアクセラレーションシステム上で実行するように設計および/または最適化されています。NVIDIAのハードウェア(GPUコアなど)とソフトウェアフレームワーク(CUDAライブラリなど)を活用することで、CPUのみのソリューションと比較して、より高速な学習と推論時間を実現しています。
## ソフトウェア統合
* ランタイムエンジン:NeMo 2.3.0
* 推奨ハードウェアマイクロアーキテクチャ互換性:
- NVIDIA Ampere
- NVIDIA Hopper
* 推奨/サポートされるオペレーティングシステム:Linux
## モデルバージョン
1.0 (2025年7月16日)
OpenReasoning-Nemotron-32B
OpenReasoning-Nemotron-14B
OpenReasoning-Nemotron-7B
OpenReasoning-Nemotron-1.5B
# 学習と評価データセット
## 学習データセット
OpenReasoning-Nemotron-7Bの学習コーパスは、[OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning)データセット、[OpenCodeReasoning-II](https://arxiv.org/abs/2507.09075)、[OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning)、および[Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset)の合成科学問題から構成されています。すべての応答は、DeepSeek-R1-0528を使用して生成されています。また、Llama-Nemotron-Post-Training-Datasetの命令追従とツール呼び出しデータもそのまま含まれています。
データ収集方法:ハイブリッド:自動、人間、合成
ラベリング方法:ハイブリッド:自動、人間、合成
特性:OpenCodeReasoningの質問(https://huggingface.co/datasets/nvidia/OpenCodeReasoning)、[OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning)、および[Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset)の合成科学問題からの500万のDeepSeek-R1-0528生成応答。また、Llama-Nemotron-Post-Training-Datasetの命令追従とツール呼び出しデータもそのまま含まれています。
## 評価データセット
モデルを包括的に評価するために、以下のベンチマークを使用しました。
### 数学
- AIME 2024/2025
- HMMT
- BRUNO 2025
### コード
- LiveCodeBench
- SciCode
### 科学
- GPQA
- MMLU-PRO
- HLE
データ収集方法:ハイブリッド:自動、人間、合成
ラベリング方法:ハイブリッド:自動、人間、合成
## 推論
**アクセラレーションエンジン**:vLLM、Tensor(RT)-LLM
**テストハードウェア**:NVIDIA H100-80GB
## 倫理的考慮事項
NVIDIAは、信頼できるAIは共同の責任であると考えており、幅広いAIアプリケーションの開発を可能にするためのポリシーと実践を策定しています。サービス利用規約に従ってダウンロードまたは使用する場合、開発者は自社の内部モデルチームと協力して、このモデルが関連する業界や使用ケースの要件を満たし、予期せぬ製品の誤用に対応することを確認する必要があります。
このモデルの倫理的考慮事項の詳細については、モデルカード++の説明性、バイアス、安全性とセキュリティ、およびプライバシーのサブカードを参照してください。
モデルの品質、リスク、セキュリティバウンダリまたはNVIDIA AIに関する懸念事項は、[こちら](https://www.nvidia.com/en-us/support/submit-security-vulnerability/)から報告してください。