🚀 ALIGN (ベースモデル)
ALIGN モデルは、Chao Jia、Yinfei Yang、Ye Xia、Yi - Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによる "Scaling Up Visual and Vision - Language Representation Learning With Noisy Text Supervision" で提案されました。ALIGNは、EfficientNet をビジョンエンコーダーとし、BERT をテキストエンコーダーとするデュアルエンコーダーアーキテクチャを持ち、コントラスト学習を用いてビジュアル表現とテキスト表現を整列させるように学習します。従来の手法とは異なり、ALIGNは大量のノイジーなデータセットを活用し、単純な方法でコーパスの規模を利用してSOTAの表現を達成できることを示しています。
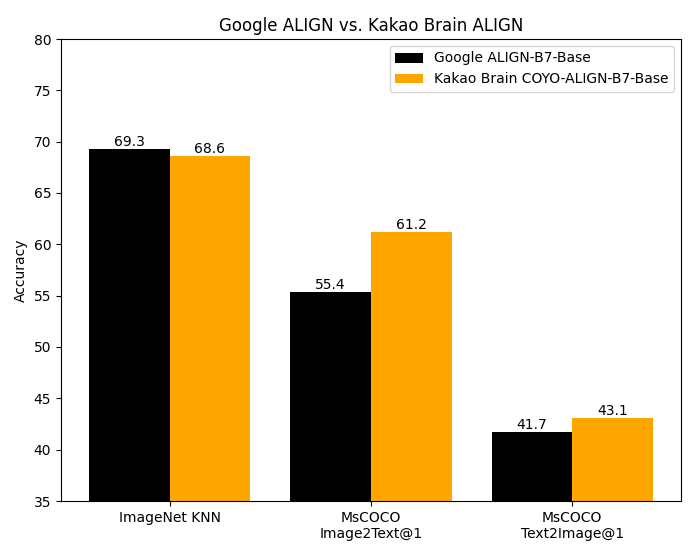
ALIGNのコードは公開されていません。このベースモデルは、Kakao Brainチームのオリジナル実装から変換されたものです。この実装は、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータを使用していますが、オープンソースの [COYO](https://github.com/kakaobrain/coyo - dataset) データセットで学習されています。Googleの ALIGN モデルは、18億の画像 - テキストペアの巨大なデータセットで学習されていますが、データセットが公開されていないため再現できません。Kakao BrainのALIGNは、はるかに小さいが慎重に選りすぐられたCOYO - 700Mデータセットで学習されているにもかかわらず、Google ALIGNの報告されたメトリクスと同等またはそれ以上の性能を示しています。
✨ 主な機能
- デュアルエンコーダーアーキテクチャを用いて、ビジュアル表現とテキスト表現を整列させる。
- 大量のノイジーなデータセットを活用し、SOTAの表現を達成する。
📦 インストール
このREADMEには具体的なインストール手順が記載されていないため、このセクションをスキップします。
📚 ドキュメント
COYO - 700Mデータセット
COYO は、Googleの ALIGN 1.8B 画像 - テキストデータセットに似た7億の画像 - テキストペアのデータセットです。これはウェブページからの「ノイジー」な代替テキストと画像のペアのコレクションで、オープンソースです。COYO - 700M と ALIGN 1.8B は、最小限のフィルタリングしか適用されていないため「ノイジー」です。COYO は他のオープンソースの画像 - テキストデータセットである LAION に似ていますが、以下の点で異なります。LAION 2B は20億の英語ペアのはるかに大きなデータセットですが、COYO の7億のペアと比較して、COYO のペアにはより多くのメタデータが付属しており、ユーザーが使用方法をより柔軟に細かく制御できます。以下の表はその違いを示しています。COYO にはすべてのペアに美的スコア、より堅牢な透かしスコア、および顔の数のデータが備わっています。
| 項目 |
COYO |
LAION 2B |
ALIGN 1.8B |
| 画像 - テキスト類似度スコア |
CLIP ViT - B/32およびViT - L/14モデルで計算された画像 - テキスト類似度スコアがメタデータとして提供されますが、可能な排除バイアスを避けるために何も除外されません |
CLIP (ViT - B/32) で提供される画像 - テキスト類似度スコア - 閾値0.28を超える例のみ |
最小限の頻度ベースのフィルタリング |
| NSFWフィルタリング |
画像とテキストのNSFWフィルタリング |
画像のNSFWフィルタリング |
Google Cloud API |
| 顔認識データ |
顔認識(顔の数)データがメタデータとして提供されます |
顔認識データなし |
該当なし |
| ペア数 |
7億の英語ペア |
20億の英語ペア |
18億 |
| データソース期間 |
CC 2020年10月 - 2021年8月 |
CC 2014 - 2020 |
該当なし |
| 美的スコア |
美的スコア |
部分的な美的スコア |
該当なし |
| 透かしスコア |
より堅牢な透かしスコア |
透かしスコア |
該当なし |
| 公開状況 |
Hugging Face Hub |
Hugging Face Hub |
公開されていません |
| 言語 |
英語 |
英語 |
英語? |
COYOは、[データセット](https://huggingface.co/datasets/kakaobrain/coyo - 700m) としてハブで利用可能です。
モデルの使用
意図された用途
このモデルは、研究コミュニティ向けの研究成果として意図されています。このモデルにより、研究者がゼロショット、任意の画像分類をよりよく理解し、探索できることを期待しています。また、このようなモデルの潜在的な影響に関する学際的研究にも利用できることを期待しています。ALIGNの論文には、このような分析の例として潜在的な下流の影響に関する議論が含まれています。
主な意図されたユーザー
これらのモデルの主な意図されたユーザーは、AI研究者です。主に、研究者がコンピュータビジョンモデルのロバスト性、汎化能力、その他の能力、バイアス、制約をよりよく理解するためにこのモデルを使用することを想定しています。
💻 使用例
基本的な使用法
ゼロショット画像分類
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
マルチモーダル埋め込み検索
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "an image of a cat"
inputs = processor(text=text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# multi-modal text embedding
text_embeds = outputs.text_embeds
# multi-modal image embedding
image_embeds = outputs.image_embeds
高度な使用法
画像またはテキストの埋め込みを個別に取得
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
# image embeddings
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
# text embeddings
text = "an image of a cat"
inputs = processor(text=text, return_tensors="pt")
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応