🚀 BigVGAN: 大規模学習による汎用ニューラルボコーダ
BigVGANは、大規模学習を行った汎用ニューラルボコーダです。このモデルは、高品質な音声合成を実現し、多様な音声タイプに対応しています。
Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
[論文] - [コード] - [展示] - [プロジェクトページ] - [重み] - [デモ]

🚀 クイックスタート
このリポジトリには、推論が容易な事前学習済みのBigVGANチェックポイントが含まれており、huggingface_hubのサポートも追加されています。
✨ 主な機能
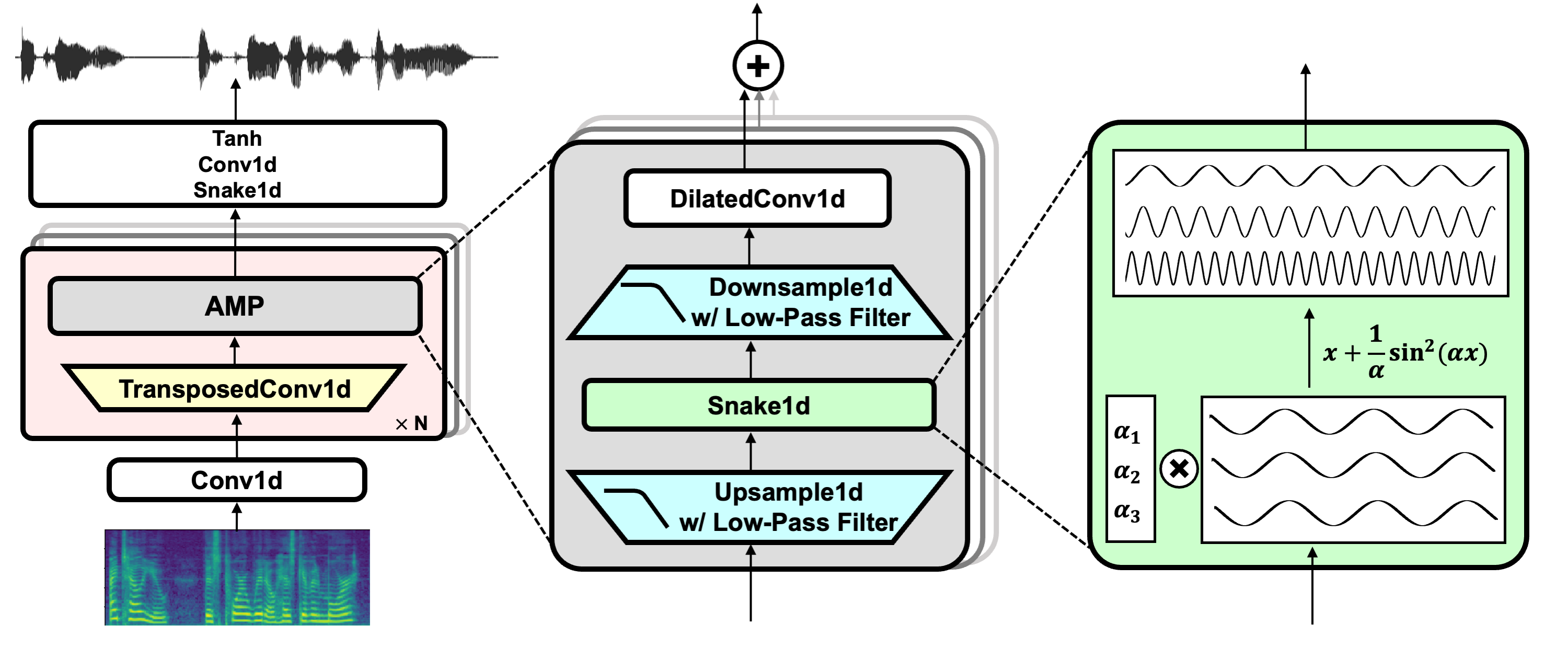
- 大規模学習により、多様な音声タイプに対応した汎用ニューラルボコーダ
- カスタムCUDAカーネルを使用した高速推論
- Hugging Face Hubとの統合による簡単な推論
📦 インストール
このリポジトリには、推論が容易な事前学習済みのBigVGANチェックポイントが含まれており、huggingface_hubのサポートも追加されています。
モデルの学習や追加機能に興味がある場合は、公式のGitHubリポジトリを参照してください: https://github.com/NVIDIA/BigVGAN
git lfs install
git clone https://huggingface.co/nvidia/bigvgan_24khz_100band
💻 使用例
基本的な使用法
以下の例では、Hugging Face Hubから事前学習済みのBigVGANジェネレータをロードし、入力波形からメルスペクトログラムを計算し、メルスペクトログラムをモデルの入力として合成波形を生成する方法を説明しています。
device = 'cuda'
import torch
import bigvgan
import librosa
from meldataset import get_mel_spectrogram
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_24khz_100band', use_cuda_kernel=False)
model.remove_weight_norm()
model = model.eval().to(device)
wav_path = '/path/to/your/audio.wav'
wav, sr = librosa.load(wav_path, sr=model.h.sampling_rate, mono=True)
wav = torch.FloatTensor(wav).unsqueeze(0)
mel = get_mel_spectrogram(wav, model.h).to(device)
with torch.inference_mode():
wav_gen = model(mel)
wav_gen_float = wav_gen.squeeze(0).cpu()
wav_gen_int16 = (wav_gen_float * 32767.0).numpy().astype('int16')
高度な使用法
カスタムCUDAカーネルを使用した合成を行うには、BigVGANをインスタンス化する際にuse_cuda_kernelパラメータを使用します。
import bigvgan
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_24khz_100band', use_cuda_kernel=True)
初めて適用するときは、nvccとninjaを使用してカーネルをビルドします。ビルドが成功すると、カーネルはalias_free_activation/cuda/buildに保存され、モデルは自動的にカーネルをロードします。コードベースはCUDA 12.1でテストされています。
システムに両方がインストールされていること、およびシステムにインストールされているnvccのバージョンがPyTorchビルドで使用されているバージョンと一致することを確認してください。
詳細については、公式のGitHubリポジトリを参照してください: https://github.com/NVIDIA/BigVGAN?tab=readme-ov-file#using-custom-cuda-kernel-for-synthesis
📚 ドキュメント
ニュース
-
2024年7月 (v2.3):
- コードの一般的なリファクタリングと改善により、可読性が向上しました。
- アンチエイリアス化された活性化関数(アップサンプリング + 活性化関数 + ダウンサンプリング)の完全に融合されたCUDAカーネルと推論速度のベンチマークが追加されました。
-
2024年7月 (v2.2): リポジトリには、gradioを使用したインタラクティブなローカルデモが含まれるようになりました。
-
2024年7月 (v2.1): BigVGANは、事前学習済みのチェックポイントを使用して🤗 Hugging Face Hubと統合され、簡単に推論を行うことができるようになりました。また、Hugging Face Spacesにインタラクティブなデモも提供しています。
-
2024年7月 (v2): BigVGAN-v2と事前学習済みのチェックポイントをリリースしました。主な特徴は以下の通りです。
- 推論用のカスタムCUDAカーネル: CUDAで記述された融合されたアップサンプリング + 活性化カーネルを提供し、推論速度を高速化します。単一のA100 GPUで1.5 - 3倍の高速化が確認されています。
- 改良された識別器と損失関数: BigVGAN-v2は、マルチスケールサブバンドCQT識別器とマルチスケールメルスペクトログラム損失を使用して学習されています。
- より大規模な学習データ: BigVGAN-v2は、複数の言語の音声、環境音、楽器音など、多様な音声タイプを含むデータセットを使用して学習されています。
- 多様な音声設定で事前学習されたBigVGAN-v2のチェックポイントを提供し、最大44 kHzのサンプリングレートと512倍のアップサンプリング比をサポートしています。
事前学習済みモデル
Hugging Face Collectionsに事前学習済みモデルを提供しています。リストされているモデルリポジトリ内で、ジェネレータの重み(bigvgan_generator.ptという名前)とその識別器/オプティマイザの状態(bigvgan_discriminator_optimizer.ptという名前)のチェックポイントをダウンロードすることができます。
📄 ライセンス
このプロジェクトはMITライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応