🚀 Karlo v1 alpha
Karloは、OpenAIのunCLIPアーキテクチャに基づくテキスト条件付き画像生成モデルです。標準の超解像モデルを改良し、64pxから256pxへの拡大を少数の逆ステップで行い、高周波の詳細を回復することができます。
🚀 クイックスタート
📦 インストール
Karloはdiffusersで利用可能です。以下のコマンドで必要なライブラリをインストールします。
pip install diffusers transformers accelerate safetensors
💻 使用例
基本的な使用法
テキストから画像への変換
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")

画像のバリエーション生成
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")

📚 ドキュメント
モデルアーキテクチャの概要
Karloは、unCLIPに基づくテキスト条件付き拡散モデルで、事前学習モデル(Prior)、デコーダー(Decoder)、超解像モジュール(SR)で構成されています。このリポジトリでは、標準の超解像モジュールを改良し、64pxから256pxへの拡大をわずか7つの逆ステップで行えるようにしています。下の図はその改良された超解像アーキテクチャを示しています。
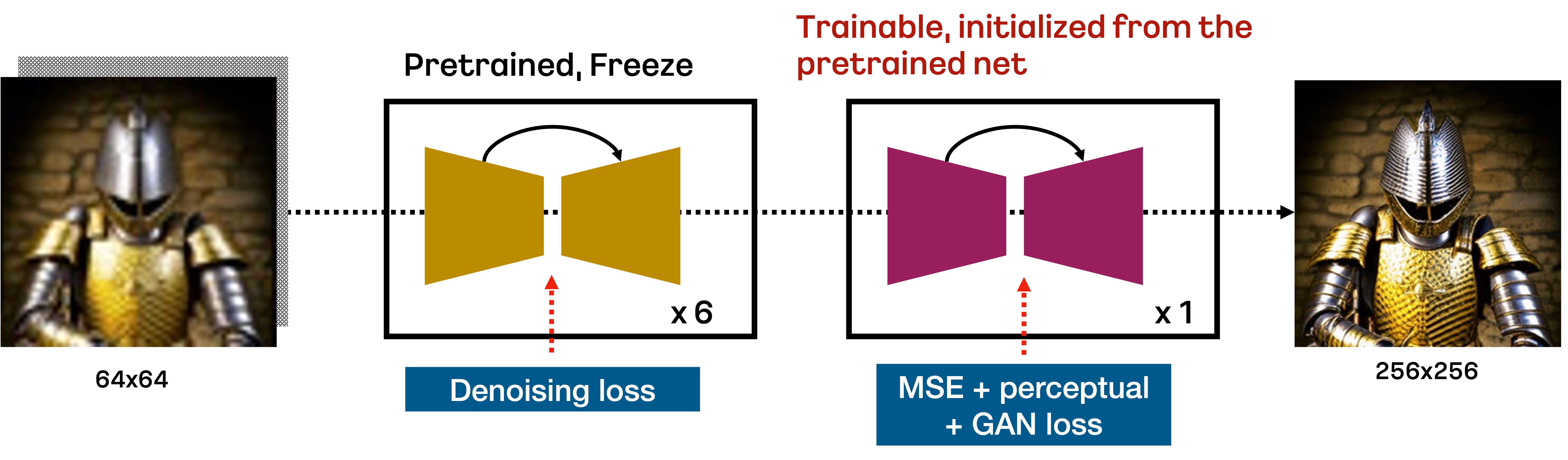
具体的には、DDPM目的で学習された標準のSRモジュールは、respacing技術に基づいて最初の6つのノイズ除去ステップで64pxから256pxへの拡大を行います。その後、VQ - GANスタイルの損失で追加学習されたSRモジュールが、最後の逆ステップを行って高周波の詳細を回復します。このアプローチは、少数の逆ステップで低解像度画像を拡大するのに非常に有効であることがわかっています。
詳細
すべてのコンポーネントは、COYO - 100M、CC3M、CC12Mを含む1億1500万の画像 - テキストペアでゼロから学習されています。PriorとDecoderの場合、OpenAIのCLIPリポジトリから提供されるViT - L/14を使用しています。unCLIPの元の実装とは異なり、デコーダー内の学習可能なトランスフォーマーをViT - L/14のテキストエンコーダーに置き換えることで効率化を図っています。SRモジュールの場合、まずDDPM目的で100万ステップ学習し、その後追加の23万4000ステップで追加コンポーネントを微調整しています。以下の表は、各コンポーネントの重要な統計情報をまとめたものです。
| コンポーネント |
Prior |
Decoder |
SR |
| CLIP |
ViT - L/14 |
ViT - L/14 |
- |
| #パラメータ |
10億 |
9億 |
7億 + 7億 |
| #最適化ステップ |
100万 |
100万 |
100万 + 20万 |
| #サンプリングステップ |
25 |
50 (デフォルト), 25 (高速) |
7 |
| チェックポイントリンク |
[ViT - L - 14](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/096db1af569b284eb76b3881534822d9/ViT - L - 14.pt), [ViT - L - 14 stats](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT - L - 14_stats.th), [モデル](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[モデル](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[モデル](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved - sr - ckpt - step%3D1.2M.ckpt) |
チェックポイントリンクのViT - L/14は元のバージョンと同等ですが、便宜上含めています。また、ViT - L - 14 - statsはPriorモジュールの出力を正規化するために必要です。
評価
Karlo - v1.0.alphaの性能をCC3MとMS - COCOの検証データセットで定量的に測定しました。以下の表はCLIPスコアとFIDを示しています。FIDを測定する際には、画像の短辺を256pxにリサイズし、中央でクロップします。すべてのケースで、PriorとDecoderの分類器フリーガイダンススケールをそれぞれ4と8に設定しました。Decoderのサンプリングステップが25であっても、モデルは合理的な性能を達成していることがわかります。
CC3M
| サンプリングステップ |
CLIP - s (ViT - B/16) |
FID (検証データ13k) |
| Prior (25) + Decoder (25) + SR (7) |
0.3081 |
14.37 |
| Prior (25) + Decoder (50) + SR (7) |
0.3086 |
13.95 |
MS - COCO
| サンプリングステップ |
CLIP - s (ViT - B/16) |
FID (検証データ30k) |
| Prior (25) + Decoder (25) + SR (7) |
0.3192 |
15.24 |
| Prior (25) + Decoder (50) + SR (7) |
0.3192 |
14.43 |
詳細な情報については、近日公開予定の技術レポートを参照してください。
学習詳細
このKarloのアルファバージョンは、[COYO](https://github.com/kakaobrain/coyo - dataset) - 100Mの高品質サブセット、CC3M、CC12Mを含む1億1500万の画像 - テキストペアで学習されています。より大規模な高品質データセットで学習されたKarloのより良いバージョンに興味がある方は、アプリケーションのランディングページB^DISCOVERをご覧ください。
📄 ライセンス
このプロジェクトはcreativeml - openrail - mライセンスの下で公開されています。
BibTex
もしこのリポジトリがあなたの研究に役立った場合は、以下のように引用してください。
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応