🚀 Kandinsky 2.1
Kandinsky 2.1は、Dall - E 2と潜在拡散のベストプラクティスを継承しつつ、いくつかの新しいアイデアを導入しています。
このモデルはCLIPモデルをテキストおよび画像エンコーダーとして使用し、CLIPモダリティの潜在空間間の拡散画像プライオ(マッピング)を利用しています。このアプローチにより、モデルの視覚的な性能が向上し、画像の合成やテキストによる画像操作に新たな可能性が開けます。
Kandinskyモデルは、Arseniy Shakhmatov、Anton Razzhigaev、Aleksandr Nikolich、Igor Pavlov、Andrey Kuznetsov、Denis Dimitrovによって作成されました。
🚀 クイックスタート
Kandinsky 2.1はdiffusersで利用可能です!
pip install diffusers transformers accelerate
💻 使用例
基本的な使用法
テキストから画像への変換
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale =1.0, height=768, width=768).images[0]
image.save("cheeseburger_monster.png")

テキストガイド付きの画像生成
from diffusers import AutoPipelineForImage2Image
import torch
import requests
from io import BytesIO
from PIL import Image
import os
pipe = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image.thumbnail((768, 768))
image = pipe(prompt=prompt, image=original_image, strength=0.3).images[0]
out.images[0].save("fantasy_land.png")

高度な使用法
補間
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
from diffusers.utils import load_image
import PIL
import torch
pipe_prior = KandinskyPriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
images_texts = ["a cat", img1, img2]
weights = [0.3, 0.3, 0.4]
prompt = ""
prior_out = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt, **prior_out, height=768, width=768).images[0]
image.save("starry_cat.png")

📚 ドキュメント
概要
Kandinsky 2.1は、unCLIPと潜在拡散に基づくテキスト条件付き拡散モデルで、トランスフォーマーベースの画像プライオモデル、Unet拡散モデル、およびデコーダーで構成されています。
モデルのアーキテクチャは以下の図に示されています。左のチャートは画像プライオモデルの学習プロセスを、中央の図はテキストから画像への生成プロセスを、右の図は画像の補間を表しています。
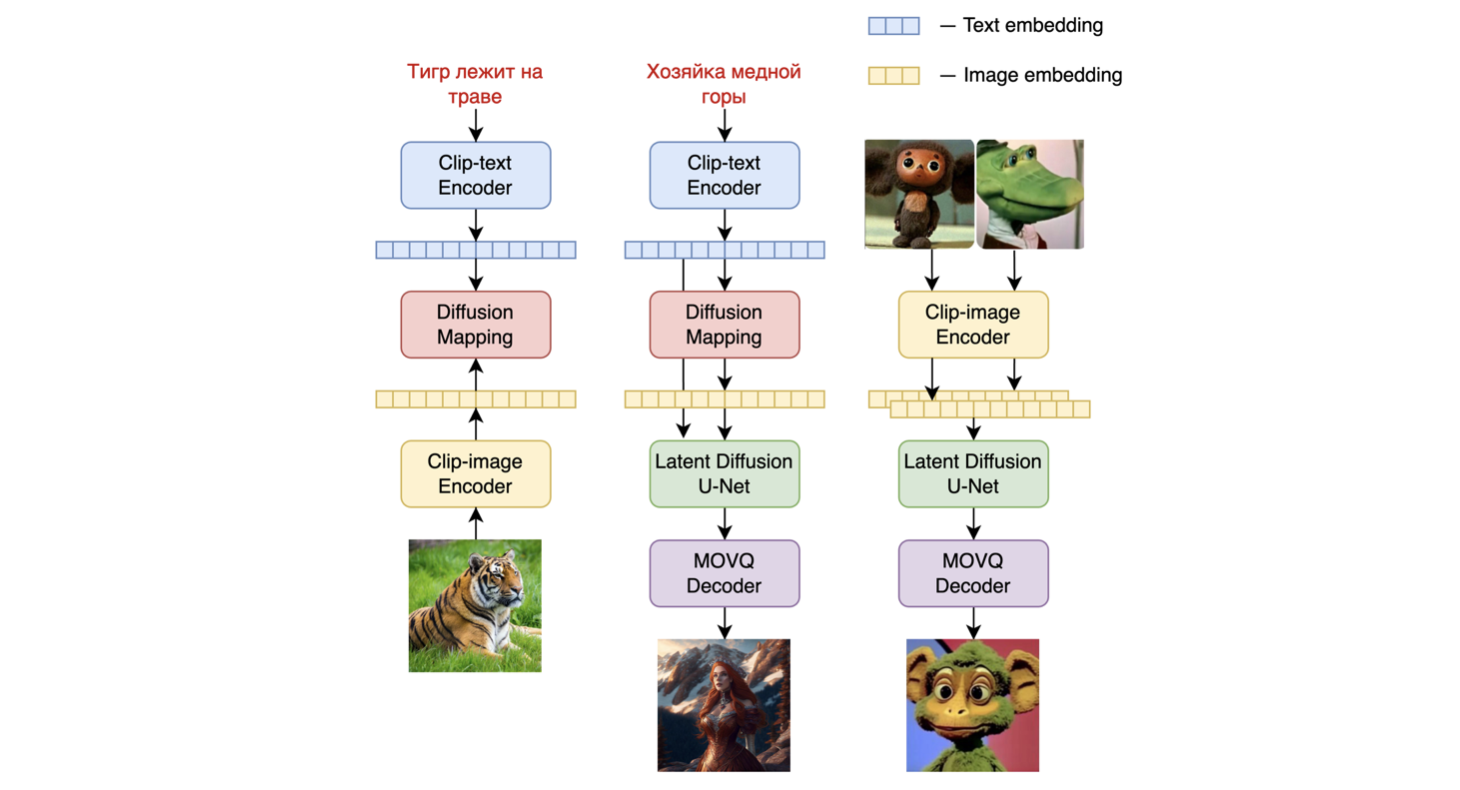
具体的には、画像プライオモデルは、事前学習されたmCLIPモデルで生成されたCLIPテキストおよび画像埋め込みを使用して学習されました。学習された画像プライオモデルは、入力テキストプロンプトのmCLIP画像埋め込みを生成するために使用されます。入力テキストプロンプトとそのmCLIP画像埋め込みの両方が拡散プロセスで使用されます。MoVQGANモデルは、潜在表現を実際の画像にデコードするモデルの最終ブロックとして機能します。
詳細
モデルの画像プライオ学習は、LAION Improved Aestheticsデータセットで行われ、その後LAION HighResデータで微調整されました。
主なText2Image拡散モデルは、LAION HighResデータセットの1億7000万のテキスト - 画像ペアを基に学習されました(重要な条件は、少なくとも768x768の解像度の画像が存在することでした)。1億7000万のペアを使用したのは、Kandinsky 2.0のUNet拡散ブロックを維持したため、最初から学習する必要がなかったからです。さらに、微調整の段階では、オープンソースから個別に収集された200万の非常に高品質な高解像度画像とその説明のデータセット(COYO、アニメ、landmarks_russiaなど)が使用されました。
評価
我々は、COCO_30kデータセットでゼロショットモードでKandinsky 2.1の性能を定量的に測定しました。以下の表はFIDを示しています。
COCO_30kにおける生成モデルのFIDメトリック値
|
FID (30k) |
| eDiff - I (2022) |
6.95 |
| Image (2022) |
7.27 |
| Kandinsky 2.1 (2023) |
8.21 |
| Stable Diffusion 2.1 (2022) |
8.59 |
| GigaGAN, 512x512 (2023) |
9.09 |
| DALL - E 2 (2022) |
10.39 |
| GLIDE (2022) |
12.24 |
| Kandinsky 1.0 (2022) |
15.40 |
| DALL - E (2021) |
17.89 |
| Kandinsky 2.0 (2022) |
20.00 |
| GLIGEN (2022) |
21.04 |
詳細な情報については、近日公開される技術レポートを参照してください。
📄 ライセンス
このプロジェクトはApache - 2.0ライセンスの下で公開されています。
BibTex
もしこのリポジトリがあなたの研究に役立った場合、以下のように引用してください。
@misc{kandinsky 2.1,
title = {kandinsky 2.1},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応