🚀 Whisper-Large-V3-French-Distil-Dec8
Whisper-Large-V3-French-Distil is a series of distilled versions of Whisper-Large-V3-French. It reduces the number of decoder layers from 32 to 16, 8, 4, or 2 and uses large-scale datasets for distillation, as described in this paper. The distilled versions reduce memory usage and inference time, maintain performance (based on the number of retained layers), and reduce the risk of hallucinations, especially in long-form transcriptions. Moreover, they can be combined with the original Whisper-Large-V3-French model for speculative decoding, improving inference speed and output consistency compared to using the standalone model. This model has been converted into various formats for use in different libraries, such as transformers, openai-whisper, fasterwhisper, whisper.cpp, candle, mlx, etc.
🚀 Quick Start
The model can be used in multiple ways, and the following sections will introduce different usage methods.
✨ Features
- Distilled Design: Reduces decoder layers and uses large-scale dataset distillation to reduce memory usage and inference time.
- Performance Maintenance: Maintains performance and reduces the risk of hallucinations, especially in long-form transcriptions.
- Speculative Decoding: Can be combined with the original model for speculative decoding, improving inference speed and output consistency.
- Multi-format Support: Converted into various formats for use in different libraries.
📦 Installation
OpenAI Whisper
pip install -U openai-whisper
Faster Whisper
pip install faster-whisper
Whisper.cpp
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
💻 Usage Examples
Hugging Face Pipeline
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec8"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
max_new_tokens=128,
)
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
Hugging Face Low-level APIs
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec8"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
predicted_ids = model.generate(
input_features.to(dtype=torch_dtype).to(device), max_new_tokens=128
)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(transcription)
Speculative Decoding
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
pipeline,
)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
assistant_model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
assistant_model.to(device)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
generate_kwargs={"assistant_model": assistant_model},
max_new_tokens=128,
)
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
OpenAI Whisper
import whisper
from datasets import load_dataset
model = whisper.load_model("./models/whisper-large-v3-french-distil-dec8/original_model.pt")
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
result = model.transcribe(sample, language="fr")
print(result["text"])
Faster Whisper
from datasets import load_dataset
from faster_whisper import WhisperModel
model = WhisperModel("./models/whisper-large-v3-french-distil-dec8/ctranslate2", device="cuda", compute_type="float16")
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
segments, info = model.transcribe(sample, beam_size=5, language="fr")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
📚 Documentation
Performance
We evaluated the model on both short and long-form transcriptions and tested it on in-distribution and out-of-distribution datasets for a comprehensive analysis of its accuracy, generalizability, and robustness. Note that the reported WER is the result after converting numbers to text, removing punctuation (except for apostrophes and hyphens), and converting all characters to lowercase. All evaluation results on public datasets can be found here.
Short-Form Transcription
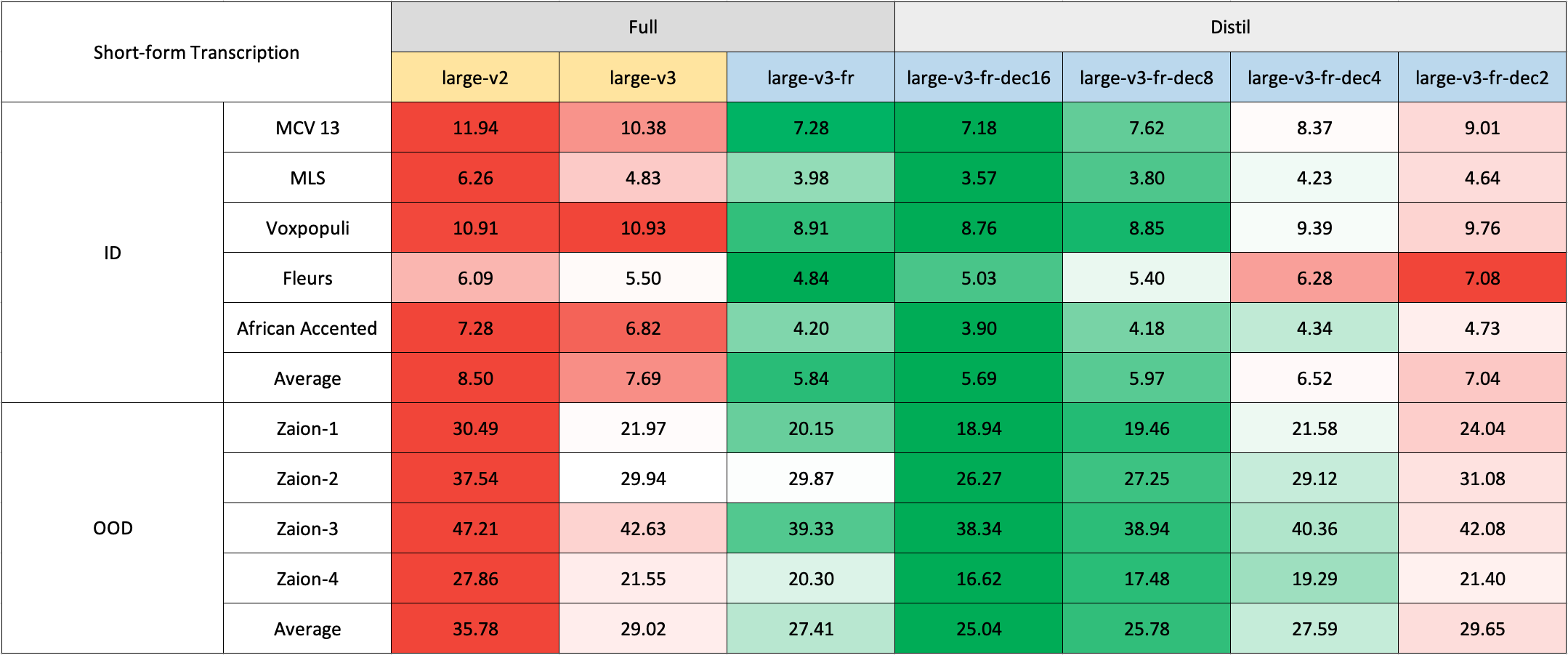 Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we used internal test sets from Zaion Lab. These sets consist of human-annotated audio-transcription pairs from call center conversations with significant background noise and domain-specific terminology.
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we used internal test sets from Zaion Lab. These sets consist of human-annotated audio-transcription pairs from call center conversations with significant background noise and domain-specific terminology.
Long-Form Transcription
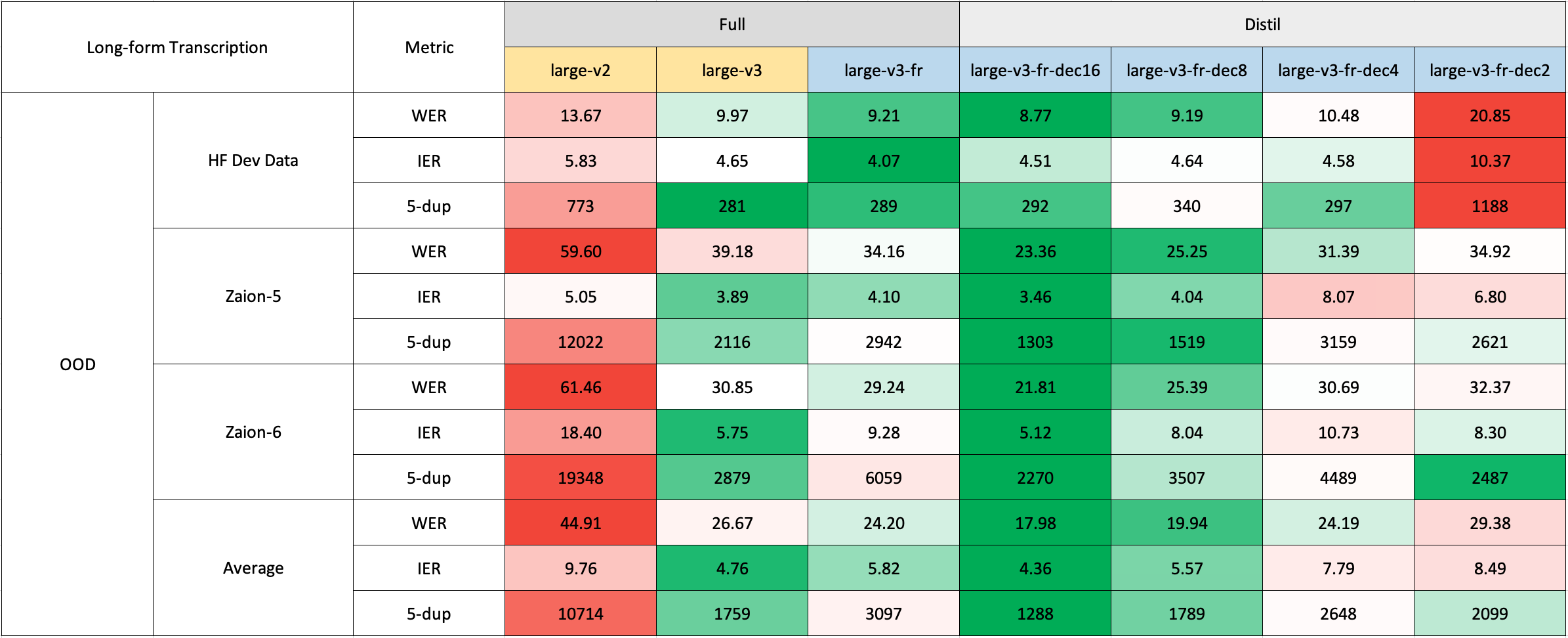 The long-form transcription was run using the 🤗 Hugging Face pipeline for quicker evaluation. Audio files were segmented into 30-second chunks and processed in parallel.
The long-form transcription was run using the 🤗 Hugging Face pipeline for quicker evaluation. Audio files were segmented into 30-second chunks and processed in parallel.
Training details
The model is a distilled version of Whisper-Large-V3-French, reducing the number of decoder layers from 32 to 16, 8, 4, or 2 and using large-scale datasets for distillation, as described in this paper.
Acknowledgements
Not provided in the original document.
📄 License
This project is licensed under the MIT license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)