%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 ToRoLaMa: The Vietnamese Instruction-Following and Chat Model
ToRoLaMa is an open - source, multi - turn large language model (LLM) jointly developed by Taureau AI in Vietnam and Torus AI in France. It initially focuses on the Vietnamese language and aims to support various international languages in the future.
🚀 Quick Start
Run the model
ToRoLaMa uses a prompt format similar to Vicuna, designed for multi - turn, high - speed, and token - efficient conversations. An example prompt is shown below for illustration.
Cuộc hội thoại giữa người dùng và một trí thông minh nhân tạo. Đưa ra câu trả lời chính xác, giúp ích cho người dùng.
USER: chào
ASSISTANT: Xin chào! Tôi có thể giúp gì cho bạn hôm nay?</s>
USER: để quản lý thời gian hiệu quả tôi nên làm thế nào??
ASSISTANT: Để quản lý thời gian hiệu quả, bạn có thể thực hiện các bước sau đây:
Lập kế hoạch: Tạo ra lịch trình hoặc danh sách công việc cần làm trong ngày hoặc tuần.
Ưu tiên công việc: Xác định công việc quan trọng và ưu tiên thực hiện trước.
Sử dụng lịch: Sử dụng lịch để theo dõi các hoạt động và sự kiện trong ngày.
Sử dụng một số công cụ hỗ trợ: Sử dụng các công cụ trực tuyến, ứng dụng điện thoại di động để giúp quản lý thời gian.
Tránh phân tâm: Tránh những việc phức tạp và không cần thiết để giải quyết trong quá trình làm việc.
Nghỉ ngơi: Để giảm căng thẳng và tăng năng suất, hãy dành thời gian nghỉ ngơi giữa các công việc.
Đánh giá và cải tiến: Đánh giá các phương pháp quản lý thời gian của bạn để tìm cách cải tiến trong tương lai.
Những cách trên sẽ giúp bạn quản lý thời gian hiệu quả hơn và tăng cường năng suất trong công việc.</s>
The file inference_hf.py in our github repository contains an example code for running ToRoLaMa model from Huggingface hub. Execute it using the following command:
python inference_hf.py
Deployment
ToRoLaMa can be easily deployed using Fastchat.
Step 1: Install fastchat
pip3 install "fschat[model_worker,webui]"
Step 2: Run the RESTful API Server
Begin by running the controller:
python3 -m fastchat.serve.controller
Next, launch the model worker:
python3 -m fastchat.serve.model_worker --model - path path - to - ToRoLaMa --conv - template vicuna_v1.1
Then, initiate the RESTful API server:
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
Finally, run the example streamlit code:
streamlit run demo.py
✨ Features
- Open - source: ToRoLaMa is an open - source LLM, allowing users to access and modify the model.
- Multi - turn: It supports multi - turn conversations, providing more natural and continuous interactions.
- Vietnamese - focused: Initially developed for the Vietnamese language, it aims to enhance language processing for Vietnamese - speaking users.
- High - performance: Trained with a diverse and extensive dataset, it aspires to match or exceed the efficiency, performance, and applicability of existing commercial LLMs.
📦 Installation
There is no specific installation content provided in the original README other than the deployment steps using Fastchat. Please refer to the Deployment section for the steps to set up the model.
📚 Documentation
Introduction
Torus AI (official name: Torus Actions SAS) was founded in Toulouse (France) in 2019 by a group of scientists under the leadership of Nguyen Tien Zung, a distinguished professor of mathematics at the University of Toulouse. The name Torus Actions comes from the toric conservation principle discovered by Zung:
Everything conserved by a dynamical system is also conserved by its associated torus actions.
Taureau AI, established in 2021 in Hanoi by Torus AI people, focuses on the development of a general - purpose AI platform, AI product engineering, and software development to serve other companies inside and outside the Torus AI ecosystem.
The common objective is to create augmented intelligence solutions that serve millions of people and make the world a happier place.
The large language model - ToRoLaMa, developed using a diverse and extensive dataset, aims to provide an enhanced understanding and representation of languages, aspiring to meet and possibly exceed the efficiency, performance, and applicability of existing commercial LLMs.
With ToRoLaMa, the goal is to contribute to the rapid progress in language processing for Vietnamese - speaking people and applications. There are also plans to extend it (and other LLMs) to other languages.
This release includes the model weights, inference code, and evaluation results for the 7B (7 billion parameter) version.
Model weights
The latest weights for ToRoLaMa can be found here:
| Date | Version | Huggingface Repo | Context Length |
|---|---|---|---|
| 19/12/2023 | ToRoLaMa - 7B - 1.0 |
[ToRoLaMa 7B 1.0](https://huggingface.co/allbyai/ToRoLaMa - 7b - v1.0) | 2048 |
Technical overview
The ToRoLaMa's pre - trained model is based on [Vietnamese - LLaMA2](https://huggingface.co/bkai - foundation - models/vietnamese - LLaMA2 - 7b - 40GB), a fine - tuned version of the LLaMA 2 model provided by bkai - foundation - labs, enhanced with a large Vietnamese - language dataset. The model was then trained using 430K high - quality, multi - turn questions/answers. Data sources for the training include [UIT - ViQUAD](https://paperswithcode.com/dataset/uit - viquad), [Bactrian - X](https://huggingface.co/datasets/MBZUAI/Bactrian - X), [Grade - school - math](https://github.com/openai/grade - school - math), etc., and in - house data that contain conversations on multiple topics.
Key advantages of ToRoLaMa include:
- Open - source availability: It is available under the LLaMA 2 License.
- Enhanced speed: With a smaller model size and an innovative [Vietnamese Tokenizer](https://huggingface.co/bkai - foundation - models/vietnamese - LLaMA2 - 7b - 40GB), whose tokens are 25% shorter compared to ChatGPT and LLaMA for Vietnamese phrases.
- Superior performance: It performs competitively against state - of - the - art models (see benchmark results below).
- Simplified deployment: It is easy to deploy for a wide range of applications.
Evaluations
The benchmark results of [Vicuna and PhoGPT](https://docs.google.com/spreadsheets/d/122ldeXuBmLSFFqaFbflj82VyYTKL - Qc2hZiTI9csc - Q/edit#gid = 44668470) were used to evaluate ToRoLaMa, and the results were compared with others using the [Fastchat MT - bench method](https://github.com/lm - sys/FastChat/tree/main/fastchat/llm_judge).
The Fastchat benchmark method, used for evaluating language models, primarily focuses on the accuracy of information in responses. However, an important aspect not accounted for in this method is the accuracy in the choice of language (English vs. Vietnamese). Both URA - LLaMA - 7B and URA - LLaMA - 13B often respond in English to Vietnamese questions. Their performance may be rated much lower when specifically benchmarked for proficiency in Vietnamese.
The benchmark scores are shown in the following table:
| Ranking | Model | Score |
|---|---|---|
| 1 | gpt - 4 | 9.52500 |
| 2 | gpt - 3.5 - turbo | 9.23750 |
| 3 | ToRoLaMa 7B | 7.31875 |
| 4 | URA - LLaMA - 13B* | 6.98750 |
| 5 | PhoGPT - 7B5 - Instruct | 6.49375 |
| 6 | Vietcuna - 7B - v3 | 5.21250 |
| 7 | URA - LLaMA - 7B* | 3.58750 |
| 8 | Vietcuna - 3B | 2.28750 |
*: The scores of URA models here do not take into account the fact that they often answer in English to questions posed in Vietnamese.
The details of the benchmark in terms of subjects are shown in the following figure (URA - LLaMA is not displayed because they generate half of the answers in English):
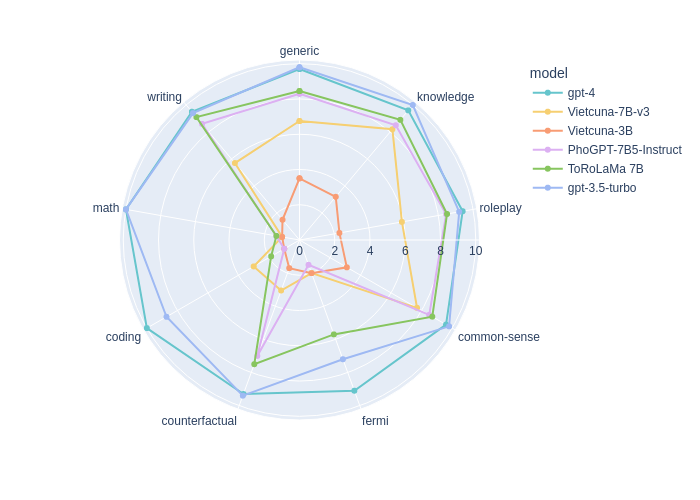
The above benchmark results show that ToRoLaMa excels in qualitative tasks compared to other models, particularly with its ability to write and answer almost on par with GPT - 3.5 - turbo. However, it shows limitations in quantitative tasks like coding and mathematics due to the nature of its training data. This suggests opportunities for future improvements in STEM - related tasks.
For detailed benchmark information and to rerun the evaluation code, refer to [Fastchat MT - bench method](https://github.com/lm - sys/FastChat/tree/main/fastchat/llm_judge). The answers from each model, the prompts, and the evaluation results are included [HERE](https://huggingface.co/allbyai/ToRoLaMa - 7b - v1.0/tree/main/mt_bench) for reproduction. The generated results can also be accessed [HERE](https://docs.google.com/spreadsheets/d/1S1UmfImrLKFtxRmdX6B5plnIIyh3RiOr/edit?usp = sharing&ouid = 102198682273617686649&rtpof = true&sd = true) for human evaluation.
🔧 Technical Details
The pre - trained model of ToRoLaMa is based on [Vietnamese - LLaMA2](https://huggingface.co/bkai - foundation - models/vietnamese - LLaMA2 - 7b - 40GB), a fine - tuned version of the LLaMA 2 model. It is enhanced with a large Vietnamese - language dataset and trained using 430K high - quality, multi - turn questions/answers. The data sources for training are diverse, including [UIT - ViQUAD](https://paperswithcode.com/dataset/uit - viquad), [Bactrian - X](https://huggingface.co/datasets/MBZUAI/Bactrian - X), [Grade - school - math](https://github.com/openai/grade - school - math), etc., as well as in - house data with multi - topic conversations.
📄 License
ToRoLaMa is licensed under the ToRoLaMa community License agreement and the LLaMA 2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.
Disclaimer
This model is derived from Meta's LLaMA - 2 model and strictly complies with the LLaMA 2 Community License Agreement. The developers explicitly declare that they offer no assurances, guarantees, or warranties about the accuracy, reliability, usability, or completeness of the model's outputs or the data presented therein. They disclaim all liability for any immediate or subsequent losses, damages, or adverse consequences arising from the use of the model. Please be aware that the model's generated content might include inaccuracies, profanity, hate speech, discriminatory remarks, and/or misleading narratives. Using this model or its derivatives for commercial purposes requires full compliance with all applicable local laws and regulations regarding the legality of the content produced by the model. The developers hold no accountability for any products or services developed using ToRoLaMa and its related files.
Acknowledgement
The [bkai - foundation - labs](https://huggingface.co/bkai - foundation - models/vietnamese - LLaMA2 - 7b - 40GB), [fastchat](https://github.com/lm - sys/FastChat/tree/main) and references therein have contributed to the development of ToRoLaMa.