🚀 Litus-ai/whisper-small-ita
This model is an optimized version of openai/whisper-small for the Italian language, offering an excellent balance between value and cost. It's ideal for scenarios with limited computational budgets but requiring accurate speech transcription.
✨ Features
This model is a version of openai/whisper-small optimized for the Italian language, trained using a portion of the proprietary data of Litus AI. litus-ai/whisper-small-ita represents a great value/cost compromise and is optimal for contexts where the computational budget is limited, but an accurate transcription of speech is still required.
Special Tokens
The main peculiarity of the model is the integration of special tokens that enrich the transcription with meta - information:
- Paralinguistic elements:
[LAUGH], [MHMH], [SIGH], [UHM]
- Audio quality:
[NOISE], [UNINT] (unintelligible)
- Speech characteristics:
[AUTOCOR] (autocorrections), [L - EN] (English code - switching)
These tokens allow for a richer transcription that captures not only the verbal content but also relevant contextual elements.
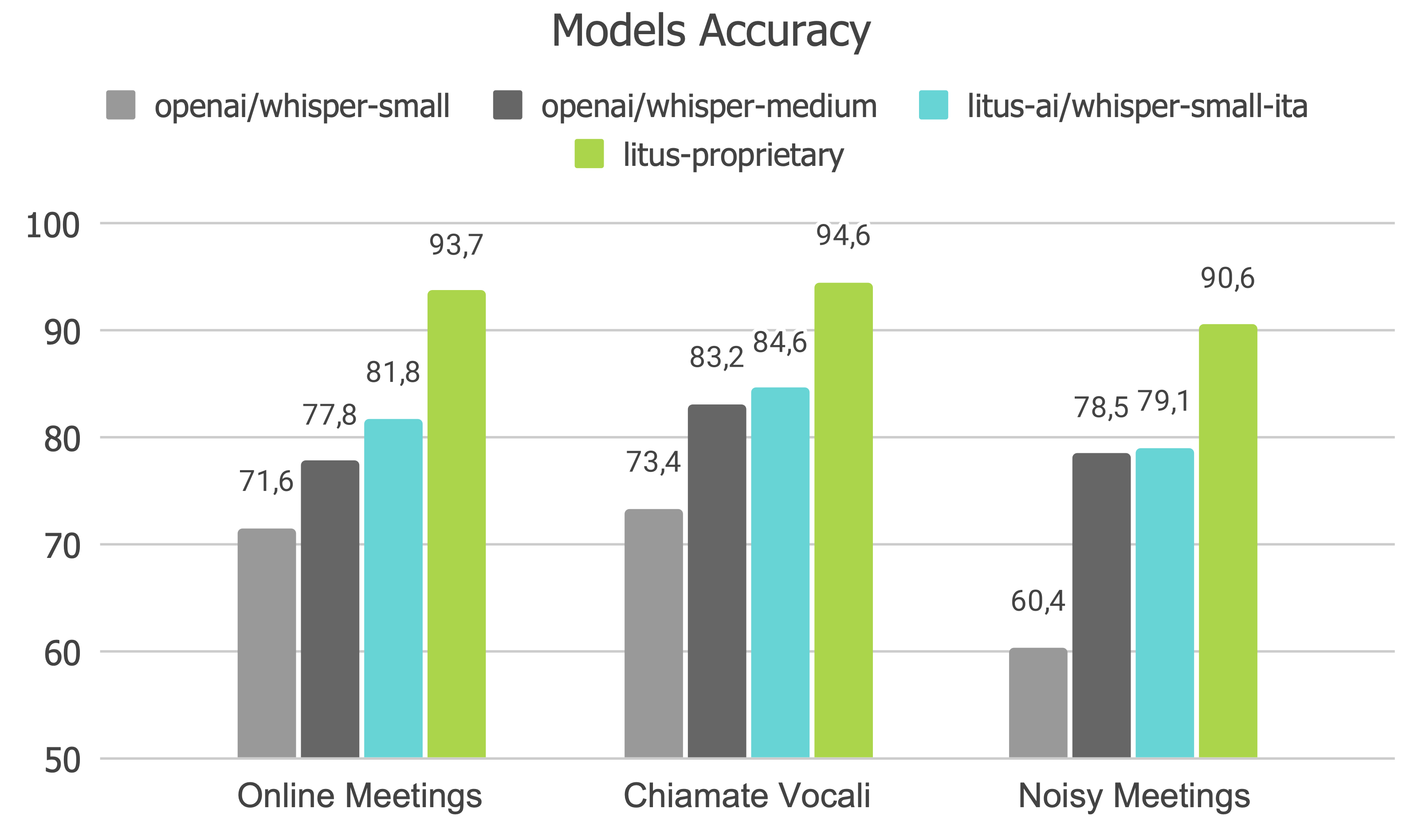
Evaluation
In the following graph, you can find the Accuracy of openai/whisper-small, openai/whisper-medium, litus-ai/whisper-small-ita, and Litus AI's proprietary model, litus-proprietary, on proprietary benchmarks for Italian meetings and voice calls.
📦 Installation
Since this model uses the transformers library, you need to install it if you haven't already. You can install it using pip:
pip install transformers datasets
💻 Usage Examples
Basic Usage
You can use litus-ai/whisper-small-ita through the "automatic-speech-recognition" pipeline of Hugging Face!
from transformers import WhisperProcessor, WhisperForConditionalGeneration
from datasets import load_dataset
model_id = "litus-ai/whisper-small-ita"
processor = WhisperProcessor.from_pretrained(model_id)
model = WhisperForConditionalGeneration.from_pretrained(model_id)
ds = load_dataset("facebook/voxpopuli", "it", split="test")
sample = ds[171]["audio"]
input_features = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
).input_features
predicted_ids = model.generate(input_features)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=False)
📚 Documentation
For any information on the architecture, the data used for pretraining, and the intended use, please refer to the Paper, the Model Card, and the Repository.
📄 License
This model is licensed under the Apache - 2.0 license.
| Property |
Details |
| Model Type |
Optimized version of openai/whisper-small for Italian |
| Training Data |
Part of the proprietary data of Litus AI |
| Pipeline Tag |
automatic - speech - recognition |
| Tags |
audio, automatic - speech - recognition, hf - asr - leaderboard |
| Library Name |
transformers |
| Metrics |
wer |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)