🚀 KR-FinBert & KR-FinBert-SC
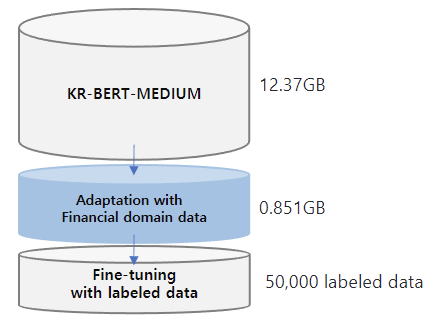
In the field of Natural Language Processing (NLP), significant progress has been made. Many studies have demonstrated that domain adaptation using a small - scale corpus and fine - tuning with labeled data can effectively improve overall performance. We proposed KR - FinBert for the financial domain by further pre - training it on a financial corpus and fine - tuning it for sentiment analysis. As shown in many studies, the performance improvement through adaptation and downstream tasks was also evident in this experiment.
🚀 Quick Start
In the NLP (Natural Language Processing) field, substantial progress has been achieved. A multitude of studies indicate that domain adaptation with a small - scale corpus and fine - tuning using labeled data are effective for enhancing overall performance. We introduced KR - FinBert for the financial domain. This was accomplished by further pre - training it on a financial corpus and fine - tuning it for sentiment analysis. Similar to many other studies, the performance improvement through adaptation and downstream tasks was also clear in this experiment.
✨ Features
- Domain - Specific Adaptation: KR - FinBert is pre - trained on a financial corpus, which is beneficial for financial - related NLP tasks.
- Sentiment Analysis Fine - Tuning: Fine - tuned for sentiment analysis, it can accurately classify financial texts' sentiment.
📦 Installation
No installation steps are provided in the original document, so this section is skipped.
📚 Documentation
Data
The training data for this model is an expansion of that of [KR - BERT - MEDIUM](https://huggingface.co/snunlp/KR - Medium), including texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center, and the [Korean Comments dataset](https://www.kaggle.com/junbumlee/kcbert - pretraining - corpus - korean - news - comments). For transfer learning, corporate - related economic news articles from 72 media sources such as the Financial Times, The Korean Economy Daily, etc., and analyst reports from 16 securities companies such as Kiwoom Securities, Samsung Securities, etc. are added. The dataset contains 440,067 news titles with their content and 11,237 analyst reports. The total data size is approximately 13.22GB. For mlm training, we split the data line by line, and the total number of lines is 6,379,315. KR - FinBert is trained for 5.5M steps with a maxlen of 512, a training batch size of 32, and a learning rate of 5e - 5. It takes 67.48 hours to train the model using an NVIDIA TITAN XP.
| Property |
Details |
| Model Type |
KR - FinBert |
| Training Data |
Expanded from KR - BERT - MEDIUM, including Korean Wikipedia texts, general news, legal texts, Korean Comments dataset, corporate - related economic news articles from 72 media sources, and analyst reports from 16 securities companies. Total data size: about 13.22GB; total number of lines for mlm training: 6,379,315 |
Downstream tasks
Sentimental Classification model
The downstream task performances are evaluated with 50,000 labeled data.
| Model |
Accuracy |
| KR - FinBert |
0.963 |
| KR - BERT - MEDIUM |
0.958 |
| KcBert - large |
0.955 |
| KcBert - base |
0.953 |
| KoBert |
0.817 |
Inference sample
| Positive |
Negative |
| 현대바이오, '폴리탁셀' 코로나19 치료 가능성에 19% 급등 |
영화관株 '코로나 빙하기' 언제 끝나나…"CJ CGV 올 4000억 손실 날수도" |
| 이수화학, 3분기 영업익 176억…전년比 80%↑ |
C쇼크에 멈춘 흑자비행…대한항공 1분기 영업적자 566억 |
| "GKL, 7년 만에 두 자릿수 매출성장 예상" |
'1000억대 횡령·배임' 최신원 회장 구속… SK네트웍스 "경영 공백 방지 최선" |
| 위지윅스튜디오, 콘텐츠 활약에 사상 첫 매출 1000억원 돌파 |
부품 공급 차질에…기아차 광주공장 전면 가동 중단 |
| 삼성전자, 2년 만에 인도 스마트폰 시장 점유율 1위 '왕좌 탈환' |
현대제철, 지난해 영업익 3,313억원···전년比 67.7% 감소 |
Citation
@misc{kr-FinBert-SC,
author = {Kim, Eunhee and Hyopil Shin},
title = {KR-FinBert: Fine-tuning KR-FinBert for Sentiment Analysis},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co/snunlp/KR-FinBert-SC}}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)