🚀 🤖 DeBERTa-v3-Large-ZeroShot-V2.0-C
This model is designed for efficient zero-shot classification, enabling classification without training data and running on both GPUs and CPUs.
🚀 Quick Start
Prerequisites
Make sure you have installed the transformers library with sentencepiece. You can install it using the following command:
Example Code
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0")
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
multi_label=False forces the model to decide on only one class. multi_label=True enables the model to choose multiple classes.
✨ Features
zeroshot-v2.0 Series of Models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
These models can do classification without training data and run on both GPUs and CPUs.
An overview of the latest zeroshot classifiers is available in my Zeroshot Classifier Collection.
The main update of this zeroshot-v2.0 series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text (entailment vs. not_entailment).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
📦 Installation
The installation mainly involves installing the transformers library. You can use the following command:
💻 Usage Examples
Basic Usage
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0")
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
Advanced Usage
You can set multi_label=True to enable the model to choose multiple classes:
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0")
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=True)
print(output)
📚 Documentation
Training Data
Models with a "-c" in the name are trained on two types of fully commercially-friendly data:
- Synthetic data generated with Mixtral-8x7B-Instruct-v0.1.
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the synthetic_zeroshot_mixtral_v0.1 dataset
in the subset
mixtral_written_text_for_tasks_v4. Data curation was done in multiple iterations and will be improved in future iterations.
- Two commercially-friendly NLI datasets: (MNLI, FEVER-NLI).
These datasets were added to increase generalization.
- Models without a "
-c" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
and all datasets in this list
where used_in_v1.1==True.
Metrics
The models were evaluated on 28 different text classification tasks with the f1_macro metric.
The main reference point is facebook/bart-large-mnli which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
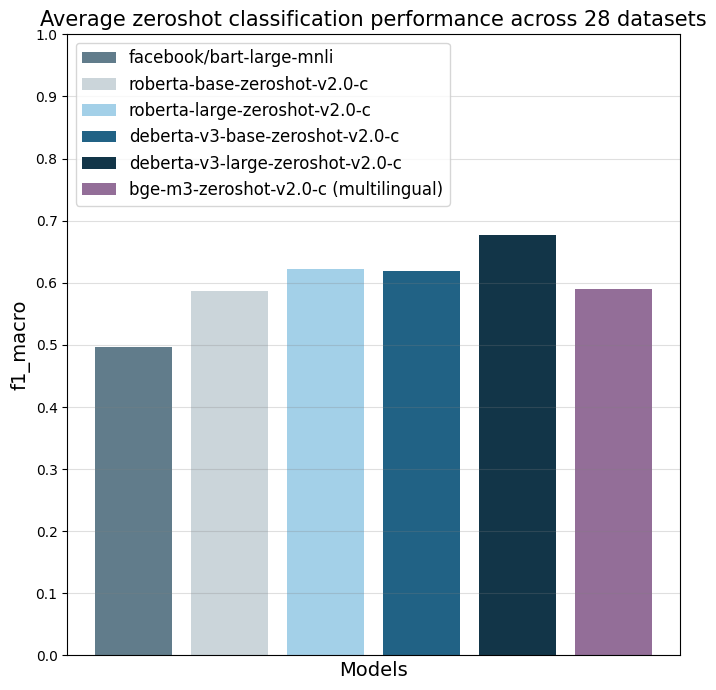
|
facebook/bart-large-mnli |
roberta-base-zeroshot-v2.0-c |
roberta-large-zeroshot-v2.0-c |
deberta-v3-base-zeroshot-v2.0-c |
deberta-v3-base-zeroshot-v2.0 (fewshot) |
deberta-v3-large-zeroshot-v2.0-c |
deberta-v3-large-zeroshot-v2.0 (fewshot) |
bge-m3-zeroshot-v2.0-c |
bge-m3-zeroshot-v2.0 (fewshot) |
| all datasets mean |
0.497 |
0.587 |
0.622 |
0.619 |
0.643 (0.834) |
0.676 |
0.673 (0.846) |
0.59 |
(0.803) |
| amazonpolarity (2) |
0.937 |
0.924 |
0.951 |
0.937 |
0.943 (0.961) |
0.952 |
0.956 (0.968) |
0.942 |
(0.951) |
| imdb (2) |
0.892 |
0.871 |
0.904 |
0.893 |
0.899 (0.936) |
0.923 |
0.918 (0.958) |
0.873 |
(0.917) |
| appreviews (2) |
0.934 |
0.913 |
0.937 |
0.938 |
0.945 (0.948) |
0.943 |
0.949 (0.962) |
0.932 |
(0.954) |
| yelpreviews (2) |
0.948 |
0.953 |
0.977 |
0.979 |
0.975 (0.989) |
0.988 |
0.985 (0.994) |
0.973 |
(0.978) |
| rottentomatoes (2) |
0.83 |
0.802 |
0.841 |
0.84 |
0.86 (0.902) |
0.869 |
0.868 (0.908) |
0.813 |
(0.866) |
| emotiondair (6) |
0.455 |
0.482 |
0.486 |
0.459 |
0.495 (0.748) |
0.499 |
0.484 (0.688) |
0.453 |
(0.697) |
| emocontext (4) |
0.497 |
0.555 |
0.63 |
0.59 |
0.592 (0.799) |
0.699 |
0.676 (0.81) |
0.61 |
(0.798) |
| empathetic (32) |
0.371 |
0.374 |
0.404 |
0.378 |
0.405 (0.53) |
0.447 |
0.478 (0.555) |
0.387 |
(0.455) |
| financialphrasebank (3) |
0.465 |
0.562 |
0.455 |
0.714 |
0.669 (0.906) |
0.691 |
0.582 (0.913) |
0.504 |
(0.895) |
| banking77 (72) |
0.312 |
0.124 |
0.29 |
0.421 |
0.446 (0.751) |
0.513 |
0.567 (0.766) |
0.387 |
(0.715) |
| massive (59) |
0.43 |
0.428 |
0.543 |
0.512 |
0.52 (0.755) |
0.526 |
0.518 (0.789) |
0.414 |
(0.692) |
| wikitoxic_toxicaggreg (2) |
0.547 |
0.751 |
0.766 |
0.751 |
0.769 (0.904) |
0.741 |
0.787 (0.911) |
0.736 |
(0.9) |
| wikitoxic_obscene (2) |
0.713 |
0.817 |
0.854 |
0.853 |
0.869 (0.922) |
0.883 |
0.893 (0.933) |
0.783 |
(0.914) |
| wikitoxic_threat (2) |
0.295 |
0.71 |
0.817 |
0.813 |
0.87 (0.946) |
0.827 |
0.879 (0.952) |
0.68 |
(0.947) |
| wikitoxic_insult (2) |
0.372 |
0.724 |
0.798 |
0.759 |
0.811 (0.912) |
0.77 |
0.779 (0.924) |
0.783 |
(0.915) |
| wikitoxic_identityhate (2) |
0.473 |
0.774 |
0.798 |
0.774 |
0.765 (0.938) |
0.797 |
0.806 (0.948) |
0.761 |
(0.931) |
| hateoffensive (3) |
0.161 |
0.352 |
0.29 |
0.315 |
0.371 (0.862) |
0.47 |
0.461 (0.847) |
0.291 |
(0.823) |
| hatexplain (3) |
0.239 |
0.396 |
0.314 |
0.376 |
0.369 (0.765) |
0.378 |
0.389 (0.764) |
0.29 |
(0.729) |
| biasframes_offensive (2) |
0.336 |
0.571 |
0.583 |
0.544 |
0.601 (0.867) |
0.644 |
0.656 (0.883) |
0.541 |
(0.855) |
| biasframes_sex (2) |
0.263 |
0.617 |
0.835 |
0.741 |
0.809 (0.922) |
0.846 |
0.815 (0.946) |
0.748 |
(0.905) |
| biasframes_intent (2) |
0.616 |
0.531 |
0.635 |
0.554 |
0.61 (0.881) |
0.696 |
0.687 (0.891) |
0.467 |
(0.868) |
| agnews (4) |
0.703 |
0.758 |
0.745 |
0.68 |
0.742 (0.898) |
0.819 |
0.771 (0.898) |
0.687 |
(0.892) |
| yahootopics (10) |
0.299 |
0.543 |
0.62 |
0.578 |
0.564 (0.722) |
0.621 |
0.613 (0.738) |
0.587 |
(0.711) |
| trueteacher (2) |
... |
... |
... |
... |
... |
... |
... |
... |
... |
📄 License
This project is licensed under the MIT license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)