%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Tangoflux
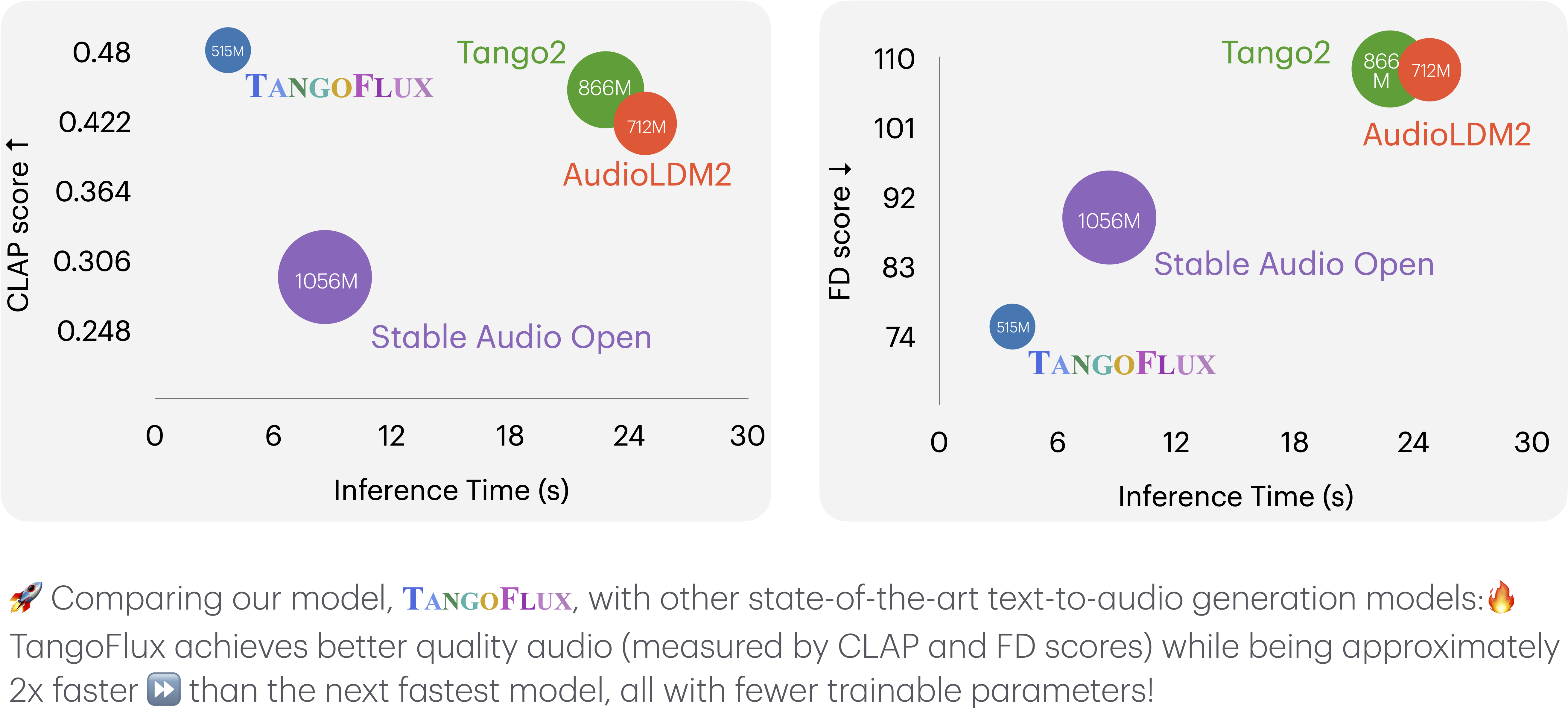
TangoFlux is an efficient text-to-audio generation system that combines flow matching and CLAP preference optimization technologies to quickly produce high-quality audio.
Downloads 727
Release Time : 12/24/2024
Model Overview
TangoFlux generates audio within 44.1kHz/30 seconds through the FluxTransformer module (including diffusion transformer and multimodal diffusion transformer), supporting text prompts and duration embeddings.
Model Features
Ultra-fast generation
Capable of generating high-quality audio in a short time, defaulting to 25 steps, with 50 steps recommended for higher quality.
High-fidelity audio
Supports 44.1kHz sampling rate, generating audio within 30 seconds while ensuring audio quality.
Multimodal support
Generates audio through text prompts and duration embeddings, supporting multimodal input.
Three-stage training process
Includes pre-training, fine-tuning, and preference optimization stages, utilizing the CRPO method to optimize model performance.
Model Capabilities
Text-to-audio generation
High-fidelity audio generation
Multimodal input processing
Use Cases
Creative content generation
Sound effect generation
Generates specific sound effects based on text descriptions, such as 'a hammer slowly hitting a wooden table'.
Produces high-quality audio files that match the description.
Multimedia applications
Background music generation
Generates background music for videos or games.
Produces background music that matches the scene.
Featured Recommended AI Models