🚀 BERTugues Base (aka "BERTugues-base-portuguese-cased")
BERTugues Base is a pre - trained model for Portuguese, aiming at tasks like Masked Language Modeling and Next Sentence Prediction, with performance improvements in multiple tasks compared to other models.
🚀 Quick Start
BERTugues was pre - trained following the steps in the original BERT paper, targeting Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). It was trained for 1 million steps using over 20 GB of text. For more training details, please read the published paper. Similar to Bertimbau, it was pre - trained with the BrWAC dataset and Portuguese Wikipedia for the Tokenizer, with some improvements in the training flow:
- Removal of uncommon Portuguese characters from Tokenizer training: In Bertimbau, more than 7000 out of 29794 tokens use oriental or special characters rarely used in Portuguese. For example, tokens like "##漫", "##켝", "##前" exist. In BERTugues, we removed these characters before training the tokenizer.
- 😀 Addition of major Emojis to the Tokenizer: Wikipedia has few Emojis in its text, resulting in a low number of Emojis in the tokens. As demonstrated in the literature, they are important for a series of tasks.
- Quality filtering of BrWAC texts: We followed the heuristic model proposed in the Gopher model paper from Google to remove low - quality texts from BrWAC.
✨ Features
Tokenizer
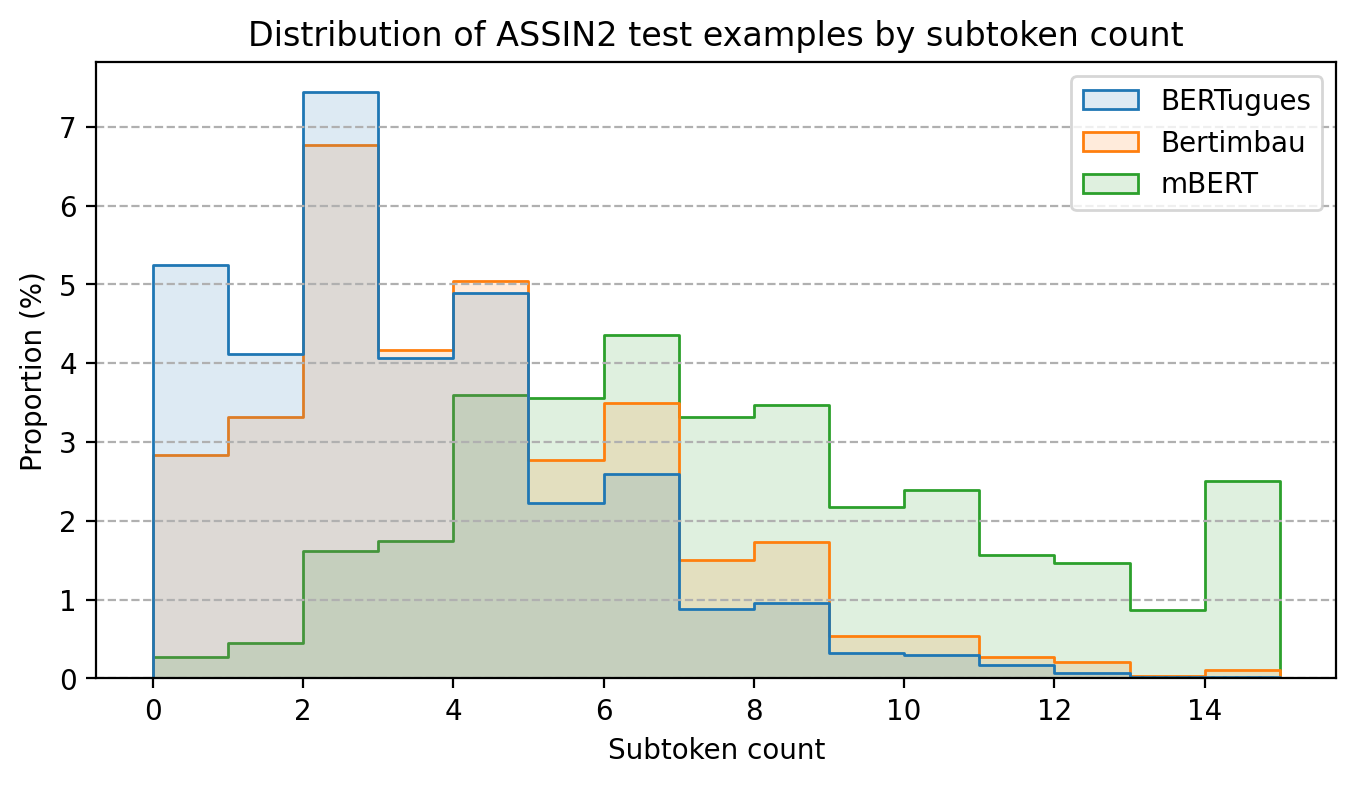
By replacing rarely used Portuguese tokens, we reduced the average number of words split into multiple tokens. In the test using assin2, the same dataset used by Bertimbau in its master's thesis test, we reduced the average number of split words per text from 3.8 to 3.0. For multilingual BERT, this number was 7.4.
Performance
To compare performance, we tested a text classification problem using the movie review dataset from IMDB, which has been translated into Portuguese and has good quality. We used the BERTugues representation of the sentence and passed it through a Random Forest model for classification.
We also used the performance comparison from the paper JurisBERT: Transformer - based model for embedding legal texts, which pre - trains a BERT specifically for texts in a domain, using multilingual BERT and Bertimbau as baselines. In this case, we used the code provided by the paper team and added BERTugues. The model is used to compare whether two texts are about the same topic.
| Model |
IMDB (F1) |
STJ (F1) |
PJERJ (F1) |
TJMS (F1) |
Average F1 |
| Multilingual BERT |
72.0% |
30.4% |
63.8% |
65.0% |
57.8% |
| Bertimbau - Base |
82.2% |
35.6% |
63.9% |
71.2% |
63.2% |
| Bertimbau - Large |
85.3% |
43.0% |
63.8% |
74.0% |
66.5% |
| BERTugues - Base |
84.0% |
45.2% |
67.5% |
70.0% |
66.7% |
BERTugues outperformed Bertimbau - base in 3 out of 4 tasks and Bertimbau - Large in 2 out of 4 tasks. Bertimbau - Large is a much larger model (3 times more parameters) and computationally expensive.
💻 Usage Examples
Basic Usage
Many usage examples are available on our GitHub. Here are 2 examples for quick reference:
Masked Language Modeling
from transformers import BertTokenizer, BertForMaskedLM, pipeline
model = BertForMaskedLM.from_pretrained("ricardoz/BERTugues-base-portuguese-cased")
tokenizer = BertTokenizer.from_pretrained("ricardoz/BERTugues-base-portuguese-cased", do_lower_case=False)
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer, top_k = 3)
pipe('[CLS] Eduardo abriu os [MASK], mas não quis se levantar. Ficou deitado e viu que horas eram.')
Sentence Embedding
from transformers import BertTokenizer, BertModel, pipeline
import torch
model = BertModel.from_pretrained("ricardoz/BERTugues-base-portuguese-cased")
tokenizer = BertTokenizer.from_pretrained("ricardoz/BERTugues-base-portuguese-cased", do_lower_case=False)
input_ids = tokenizer.encode('[CLS] Eduardo abriu os olhos, mas não quis se levantar. Ficou deitado e viu que horas eram.', return_tensors='pt')
with torch.no_grad():
last_hidden_state = model(input_ids).last_hidden_state[:, 0]
last_hidden_state
📄 License
This model is under the "other" license.
📚 Documentation
Citation
If you use BERTugues in your publications, please cite it! It helps a lot in the recognition and appreciation of the model in the scientific community.
@article{Zago2024bertugues,
title = {BERTugues: A Novel BERT Transformer Model Pre-trained for Brazilian Portuguese},
volume = {45},
url = {https://ojs.uel.br/revistas/uel/index.php/semexatas/article/view/50630},
DOI = {10.5433/1679-0375.2024.v45.50630},
journal = {Semina: Ciências Exatas e Tecnológicas},
author = {Mazza Zago, Ricardo and Agnoletti dos Santos Pedotti, Luciane},
year = {2024},
month = {Dec.},
pages = {e50630}
}
More Information
For more information, please visit our GitHub!
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)