🚀 MiniCPM-V 2.6
A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone. This model can handle various image and video tasks with high efficiency and performance.
GitHub | Demo
✨ Features
MiniCPM-V 2.6 is the latest and most capable model in the MiniCPM-V series. Built on SigLip - 400M and Qwen2 - 7B with a total of 8B parameters, it offers significant improvements over MiniCPM-Llama3-V 2.5 and introduces new features for multi - image and video understanding.
-
🔥 Leading Performance.
MiniCPM-V 2.6 achieves an average score of 65.2 on the latest version of OpenCompass, a comprehensive evaluation over 8 popular benchmarks. With only 8B parameters, it surpasses widely used proprietary models like GPT-4o mini, GPT-4V, Gemini 1.5 Pro, and Claude 3.5 Sonnet for single image understanding.
-
🖼️ Multi Image Understanding and In-context Learning. MiniCPM-V 2.6 can perform conversation and reasoning over multiple images. It achieves state-of-the-art performance on popular multi-image benchmarks such as Mantis-Eval, BLINK, Mathverse mv and Sciverse mv, and also shows promising in-context learning capability.
-
🎬 Video Understanding. MiniCPM-V 2.6 can accept video inputs, performing conversation and providing dense captions for spatial-temporal information. It outperforms GPT-4V, Claude 3.5 Sonnet and LLaVA-NeXT-Video-34B on Video-MME with/without subtitles.
-
💪 Strong OCR Capability and Others.
MiniCPM-V 2.6 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344). It achieves state-of-the-art performance on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V, and Gemini 1.5 Pro.
Based on the latest RLAIF-V and VisCPM techniques, it features trustworthy behaviors, with significantly lower hallucination rates than GPT-4o and GPT-4V on Object HalBench, and supports multilingual capabilities on English, Chinese, German, French, Italian, Korean, etc.
-
🚀 Superior Efficiency.
In addition to its friendly size, MiniCPM-V 2.6 also shows state-of-the-art token density (i.e., number of pixels encoded into each visual token). It produces only 640 tokens when processing a 1.8M pixel image, which is 75% fewer than most models. This directly improves the inference speed, first-token latency, memory usage, and power consumption. As a result, MiniCPM-V 2.6 can efficiently support real-time video understanding on end-side devices such as iPad.
-
💫 Easy Usage.
MiniCPM-V 2.6 can be easily used in various ways: (1) llama.cpp and ollama support for efficient CPU inference on local devices, (2) int4 and GGUF format quantized models in 16 sizes, (3) vLLM support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks, (5) quick local WebUI demo setup with Gradio and (6) online web demo.
Evaluation
Single image results on OpenCompass, MME, MMVet, OCRBench, MMMU, MathVista, MMB, AI2D, TextVQA, DocVQA, HallusionBench, Object HalBench:

* We evaluate this benchmark using chain-of-thought prompting.
+ Token Density: number of pixels encoded into each visual token at maximum resolution, i.e., # pixels at maximum resolution / # visual tokens.
Note: For proprietary models, we calculate token density based on the image encoding charging strategy defined in the official API documentation, which provides an upper-bound estimation.
Click to view multi-image results on Mantis Eval, BLINK Val, Mathverse mv, Sciverse mv, MIRB.
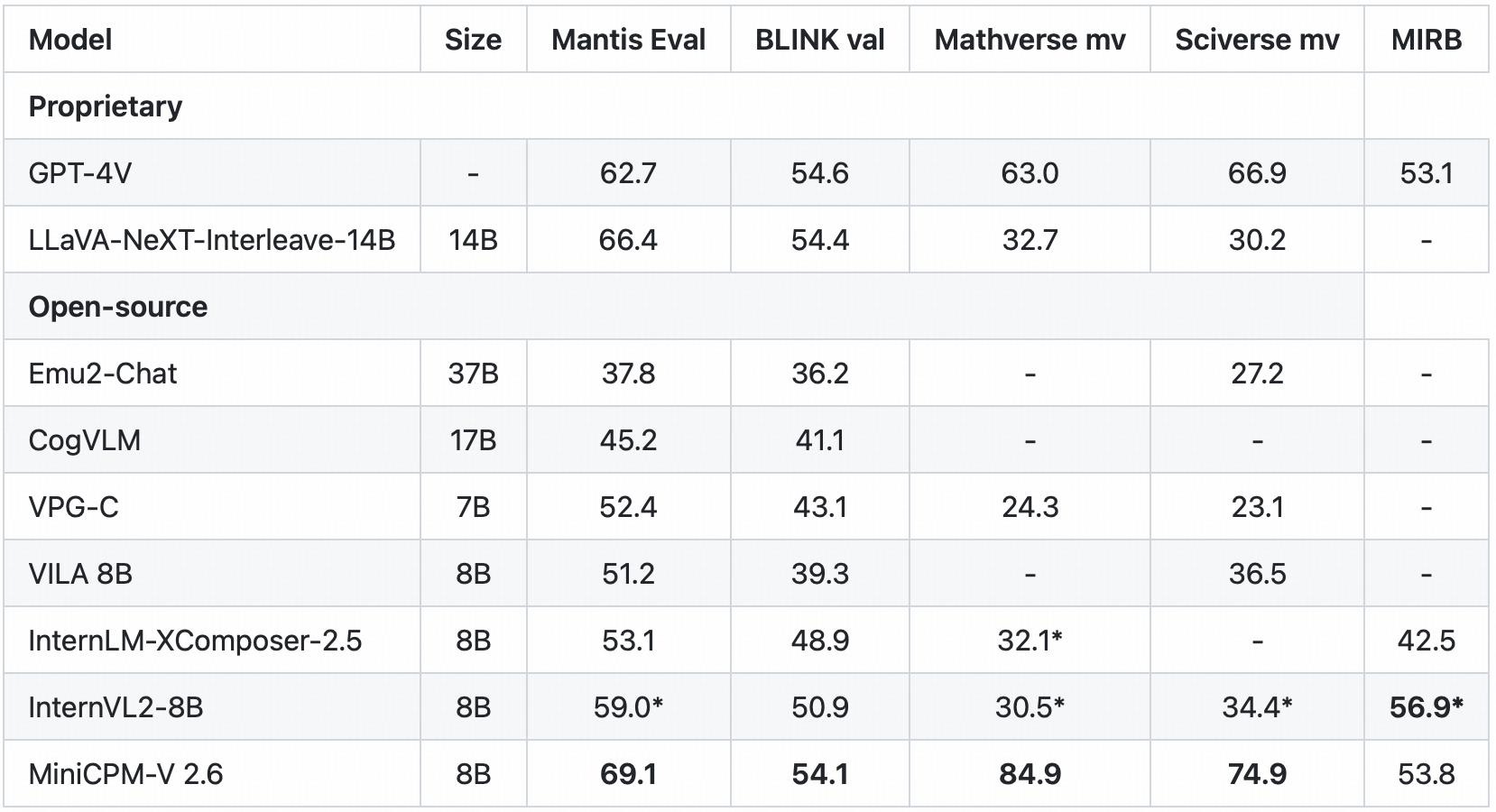
* We evaluate the officially released checkpoint by ourselves.
Click to view video results on Video-MME and Video-ChatGPT.

Click to view few-shot results on TextVQA, VizWiz, VQAv2, OK-VQA.

* denotes zero image shot and two additional text shots following Flamingo.
+ We evaluate the pretraining ckpt without SFT.
Examples
Click to view more cases.
We deploy MiniCPM-V 2.6 on end devices. The demo video is the raw screen recording on a iPad Pro without edition.
🚀 Quick Start
Click here to try the Demo of MiniCPM-V 2.6.
💻 Usage Examples
Basic Usage
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
Pillow==10.1.0
torch==2.1.2
torchvision==0.16.2
transformers==4.40.0
sentencepiece==0.1.99
decord
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')
Advanced Usage
Chat with multiple images
Click to show Python code running MiniCPM-V 2.6 with multiple images input.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
In-context few-shot learning
Click to view Python code running MiniCPM-V 2.6 with few-shot input.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')
msgs = [
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
{'role': 'user', 'content': [image_test, question]}
]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
Chat with video
Click to view Python code running MiniCPM-V 2.6 with video input.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
MAX_NUM_FRAMES=64
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1)
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path ="video_test.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
params={}
params["use_image_id"] = False
params["max_slice_nums"] = 2
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
params=params
)
print(answer)
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)











