🚀 🐱 Sana Model Card
This is a scalable Linear - Diffusion - Transformer - based text - to - image generative model, which can generate and modify images based on text prompts. It uses efficient techniques to achieve better performance while saving training costs.

✨ Features
We introduce SANA - 1.5, an efficient model with scaling of training - time and inference time techniques. SANA - 1.5 delivers:
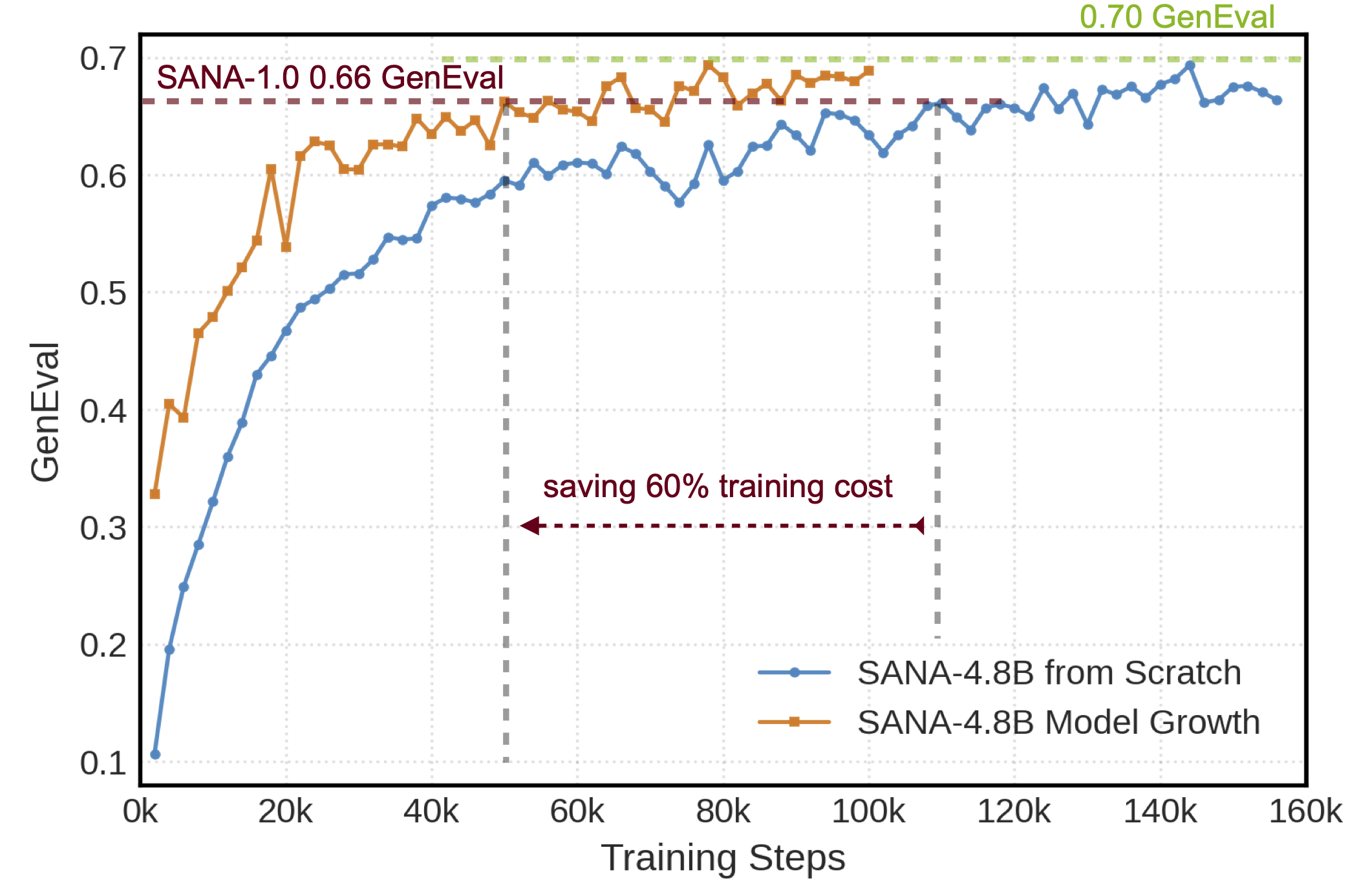
- Efficient model growth: From 1.6B Sana - 1.0 model to 4.8B, achieving similar or better performance than training from scratch and saving 60% training cost.
- Efficient model depth pruning: Slimming any model size as you want.
- Powerful VLM selection based inference scaling: Smaller model + inference scaling > larger model.
- Top - notch GenEval & DPGBench results.
Source code is available at https://github.com/NVlabs/Sana.
📚 Documentation
Model Description
| Property |
Details |
| Developed by |
NVIDIA, Sana |
| Model type |
Scalable Linear - Diffusion - Transformer - based text - to - image generative model |
| Model size |
4.8B parameters |
| Model precision |
torch.bfloat16 (BF16) |
| Model resolution |
This model is developed to generate 1024px based images with multi - scale height and width. |
| License |
NSCL v2 - custom. Governing Terms: NVIDIA License. Additional Information: [Gemma Terms of Use |
| Model Description |
This is a model that can be used to generate and modify images based on text prompts. It is a Linear Diffusion Transformer that uses one fixed, pretrained text encoders ([Gemma2 - 2B - IT](https://huggingface.co/google/gemma - 2 - 2b - it)) and one 32x spatial - compressed latent feature encoder ([DC - AE](https://hanlab.mit.edu/projects/dc - ae)). |
| Resources for more information |
Check out our GitHub Repository and the SANA - 1.5 report on arXiv. |
Model Sources
For research purposes, we recommend our generative - models Github repository (https://github.com/NVlabs/Sana), which is more suitable for both training and inference and for which most advanced diffusion sampler like Flow - DPM - Solver is integrated. [MIT Han - Lab](https://nv - sana.mit.edu/) provides free Sana inference.
- Repository: https://github.com/NVlabs/Sana
- Demo: https://nv - sana.mit.edu/
🧨 Diffusers
Developing
📄 Uses
Direct Use
The model is intended for research purposes only. Possible research areas and tasks include:
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
Out - of - Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out - of - scope for the abilities of this model.
🔧 Technical Details
Limitations
- The model does not achieve perfect photorealism.
- The model cannot render complex legible text.
- Fingers, etc. in general may not be generated properly.
- The autoencoding part of the model is lossy.
Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)






 Safetensors
Safetensors