🚀 Kandinsky 2.1
Kandinsky 2.1继承了Dall - E 2和潜在扩散模型的最佳实践,同时引入了一些新思路。它利用CLIP模型作为文本和图像编码器,并在CLIP模态的潜在空间之间使用扩散图像先验(映射)。这种方法提升了模型的视觉性能,为图像融合和文本引导的图像操作开辟了新的前景。
该Kandinsky模型由Arseniy Shakhmatov、Anton Razzhigaev、Aleksandr Nikolich、Igor Pavlov、Andrey Kuznetsov和Denis Dimitrov创建。
🚀 快速开始
Kandinsky 2.1可在diffusers库中使用!
pip install diffusers transformers accelerate
✨ 主要特性
Kandinsky 2.1继承了Dall - E 2和潜在扩散模型的优点,引入新思想,使用CLIP模型作为文本和图像编码器,利用扩散图像先验提升视觉性能,支持文本引导的图像生成和修复等操作。
📦 安装指南
pip install diffusers transformers accelerate
💻 使用示例
基础用法
以下是文本引导的图像修复生成示例:
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image
import torch
import numpy as np
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "a hat"
negative_prompt = "low quality, bad quality"
original_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
mask = np.zeros((768, 768), dtype=np.float32)
mask[:250, 250:-250] = 1
image = pipe(prompt=prompt, image=original_image, mask_image=mask).images[0]
image.save("cat_with_hat.png")

高级用法
关于Kandinsky图像修复的重大变更
我们在以下拉取请求中对Kandinsky图像修复管道进行了重大更改:https://github.com/huggingface/diffusers/pull/4207。之前我们接受的掩码格式是黑色像素表示被掩码的区域,这与diffusers中的所有其他管道不一致。我们已经更改了Kandinsky中的掩码格式,现在使用白色像素表示被掩码的区域。
如果您在生产环境中使用Kandinsky图像修复,请升级您的代码以遵循上述更改。您现在需要将掩码更改为:
import PIL.ImageOps
mask = PIL.ImageOps.invert(mask)
mask = 1 - mask
📚 详细文档
模型架构概述
Kandinsky 2.1是一个基于unCLIP和潜在扩散的文本条件扩散模型,由基于Transformer的图像先验模型、Unet扩散模型和解码器组成。
模型架构如下图所示 - 左侧的图表描述了训练图像先验模型的过程,中间的图是文本到图像的生成过程,右侧的图是图像插值。
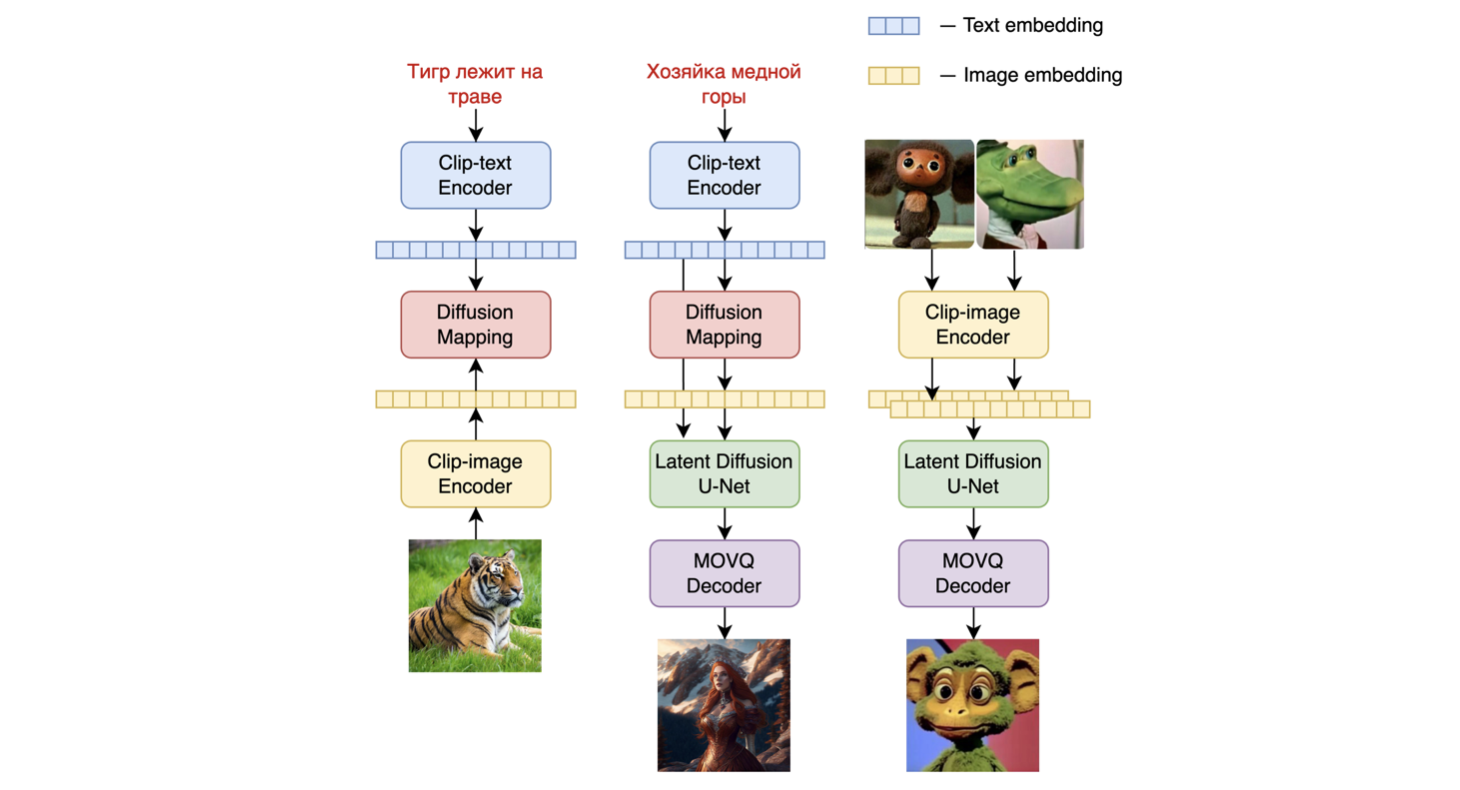
具体来说,图像先验模型是在使用预训练的[mCLIP模型](https://huggingface.co/M-CLIP/XLM - Roberta - Large - Vit - L - 14)生成的CLIP文本和图像嵌入上进行训练的。训练好的图像先验模型然后用于为输入文本提示生成mCLIP图像嵌入。输入文本提示及其mCLIP图像嵌入都在扩散过程中使用。[MoVQGAN](https://openreview.net/forum?id=Qb - AoSw4Jnm)模型作为模型的最后一个模块,将潜在表示解码为实际图像。
模型训练细节
- 图像先验训练:模型的图像先验训练是在LAION Improved Aesthetics数据集上进行的,然后在[LAION HighRes数据](https://huggingface.co/datasets/laion/laion - high - resolution)上进行微调。
- 主文本到图像扩散模型训练:主文本到图像扩散模型是在来自[LAION HighRes数据集](https://huggingface.co/datasets/laion/laion - high - resolution)的1.7亿个文本 - 图像对上进行训练的(一个重要条件是存在分辨率至少为768x768的图像)。使用1.7亿对是因为我们保留了Kandinsky 2.0中的UNet扩散块,这使我们不必从头开始训练它。此外,在微调阶段,使用了一个从开放源单独收集的包含200万个非常高质量的高分辨率图像及其描述的数据集(COYO、动漫、俄罗斯地标等)。
模型评估
我们在COCO_30k数据集上以零样本模式定量测量了Kandinsky 2.1的性能。下表展示了FID指标。
生成模型在COCO_30k上的FID指标值
|
FID (30k) |
| eDiff - I (2022) |
6.95 |
| Image (2022) |
7.27 |
| Kandinsky 2.1 (2023) |
8.21 |
| Stable Diffusion 2.1 (2022) |
8.59 |
| GigaGAN, 512x512 (2023) |
9.09 |
| DALL - E 2 (2022) |
10.39 |
| GLIDE (2022) |
12.24 |
| Kandinsky 1.0 (2022) |
15.40 |
| DALL - E (2021) |
17.89 |
| Kandinsky 2.0 (2022) |
20.00 |
| GLIGEN (2022) |
21.04 |
更多信息,请参考即将发布的技术报告。
📄 许可证
本项目采用Apache 2.0许可证。
BibTex
如果您在研究中发现此仓库有用,请引用:
@misc{kandinsky 2.1,
title = {kandinsky 2.1},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言