🚀 Minerva-7B-instruct-v1.0模型介紹
Minerva是首個完全基於意大利語從頭開始預訓練的大語言模型(LLM)家族。它由Sapienza NLP在未來人工智能研究(FAIR)項目框架下開發,與CINECA合作,並得到了Babelscape和CREATIVE PRIN項目的額外支持。值得注意的是,Minerva模型是真正開放(數據和模型)的意大利語 - 英語大語言模型,大約一半的預訓練數據包含意大利語文本。
🚀 快速開始
如何使用Hugging Face Transformers調用Minerva
import transformers
import torch
model_id = "sapienzanlp/Minerva-7B-instruct-v1.0"
pipeline = transformers.pipeline(
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
input_conv = [{"role": "user", "content": "Qual è la capitale dell'Italia?"}]
output = pipeline(
input_conv,
max_new_tokens=128,
)
output
[{'generated_text': [{'role': 'user', 'content': "Qual è la capitale dell'Italia?"}, {'role': 'assistant', 'content': "La capitale dell'Italia è Roma."}]}]
✨ 主要特性
Minerva-7B-instruct-v1.0是一個擁有70億參數的模型,在近2.5萬億個標記(1.14萬億個意大利語標記、1.14萬億個英語標記和2000億個代碼標記)上進行了訓練。該模型屬於Minerva大語言模型家族,該家族還包括:
🔧 技術細節
模型架構
Minerva-7B-base-v1.0是一個基於Mistral架構的Transformer模型。有關該模型超參數的詳細分解,請查看配置文件。
Minerva大語言模型家族的構成如下:
| 模型名稱 |
標記數 |
層數 |
隱藏層大小 |
注意力頭數 |
KV頭數 |
滑動窗口 |
最大上下文長度 |
| Minerva-350M-base-v1.0 |
700億 (350億意大利語 + 350億英語) |
16 |
1152 |
16 |
4 |
2048 |
16384 |
| Minerva-1B-base-v1.0 |
2000億 (1000億意大利語 + 1000億英語) |
16 |
2048 |
16 |
4 |
2048 |
16384 |
| Minerva-3B-base-v1.0 |
6600億 (3300億意大利語 + 3300億英語) |
32 |
2560 |
32 |
8 |
2048 |
16384 |
| Minerva-7B-base-v1.0 |
2.48萬億 (1.14萬億意大利語 + 1.14萬億英語 + 2000億代碼) |
32 |
4096 |
32 |
8 |
無 |
4096 |
模型訓練
Minerva-7B-base-v1.0使用來自MosaicML的llm-foundry 0.8.0進行訓練。所使用的超參數如下:
| 模型名稱 |
優化器 |
學習率 |
貝塔係數 |
誤差 |
權重衰減 |
調度器 |
預熱步數 |
批量大小(標記) |
總步數 |
| Minerva-350M-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
餘弦 |
2% |
400萬 |
16690 |
| Minerva-1B-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
餘弦 |
2% |
400萬 |
47684 |
| Minerva-3B-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
餘弦 |
2% |
400萬 |
157357 |
| Minerva-7B-base-v1.0 |
AdamW |
3e-4 |
(0.9, 0.95) |
1e-5 |
0.1 |
餘弦 |
2000 |
400萬 |
591558 |
SFT訓練
SFT模型使用Llama-Factory進行訓練。數據混合情況如下:
| 數據集 |
來源 |
代碼數據量 |
英語數據量 |
意大利語數據量 |
| Glaive-code-assistant |
鏈接 |
100000 |
0 |
0 |
| Alpaca-python |
鏈接 |
20000 |
0 |
0 |
| Alpaca-cleaned |
鏈接 |
0 |
50000 |
0 |
| Databricks-dolly-15k |
鏈接 |
0 |
15011 |
0 |
| No-robots |
鏈接 |
0 |
9499 |
0 |
| OASST2 |
鏈接 |
0 |
29000 |
528 |
| WizardLM |
鏈接 |
0 |
29810 |
0 |
| LIMA |
鏈接 |
0 |
1000 |
0 |
| OPENORCA |
鏈接 |
0 |
30000 |
0 |
| Ultrachat |
鏈接 |
0 |
50000 |
0 |
| MagpieMT |
鏈接 |
0 |
30000 |
0 |
| Tulu-V2-Science |
鏈接 |
0 |
7000 |
0 |
| Aya_datasets |
鏈接 |
0 |
3944 |
738 |
| Tower-blocks_it |
鏈接 |
0 |
0 |
7276 |
| Bactrian-X |
鏈接 |
0 |
0 |
67000 |
| Magpie (我們翻譯的) |
鏈接 |
0 |
0 |
59070 |
| Everyday-conversations (我們翻譯的) |
鏈接 |
0 |
0 |
2260 |
| alpaca-gpt4-it |
鏈接 |
0 |
0 |
15000 |
| capybara-claude-15k-ita |
鏈接 |
0 |
0 |
15000 |
| Wildchat |
鏈接 |
0 |
0 |
5000 |
| GPT4_INST |
鏈接 |
0 |
0 |
10000 |
| Italian Safety Instructions |
- |
0 |
0 |
21426 |
| Italian Conversations |
- |
0 |
0 |
4843 |
更多詳細信息,請查看我們的技術頁面。
在線DPO訓練
本模型卡是關於我們的DPO模型的。直接偏好優化(DPO)是一種基於用戶反饋來優化模型的方法,類似於基於人類反饋的強化學習(RLHF),但無需強化學習的複雜性。在線DPO通過在訓練過程中實現即時自適應進一步改進了這一點,利用新的反饋不斷優化模型。在訓練此模型時,我們使用了Hugging Face TRL庫和在線DPO,並使用Skywork/Skywork-Reward-Llama-3.1-8B-v0.2模型作為評判器來評估和指導優化。在此階段,我們僅使用了來自HuggingFaceH4/ultrafeedback_binarized(英語)、efederici/evol-dpo-ita(意大利語)和Babelscape/ALERT(翻譯成意大利語)的提示,並添加了額外的手動整理數據以確保安全性。
更多詳細信息,請查看我們的技術頁面。
分詞器豐富度
分詞器豐富度衡量的是每個分詞後的單詞平均產生的標記數量。在特定語言中表現出高豐富度值的分詞器通常表明它會對該語言的單詞進行廣泛的切分。分詞器豐富度與模型在特定語言上的推理速度密切相關,因為較高的值意味著需要生成更長的標記序列,從而降低推理速度。
基於Cultura X(CX)數據和維基百科(Wp)樣本計算的豐富度:
| 模型 |
詞彙表大小 |
意大利語豐富度(CX) |
英語豐富度(CX) |
意大利語豐富度(Wp) |
英語豐富度(Wp) |
| Mistral-7B-v0.1 |
32000 |
1.87 |
1.32 |
2.05 |
1.57 |
| gemma-7b |
256000 |
1.42 |
1.18 |
1.56 |
1.34 |
| Minerva-3B-base-v1.0 |
32768 |
1.39 |
1.32 |
1.66 |
1.59 |
| Minerva-7B-base-v1.0 |
51200 |
1.32 |
1.26 |
1.56 |
1.51 |
📚 詳細文檔
模型評估
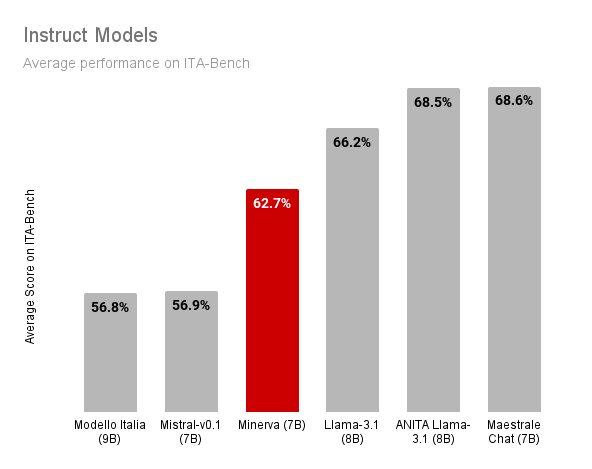
在評估Minerva時,我們使用了ITA-Bench,這是一個用於測試意大利語模型能力的新評估套件。ITA-Bench由18個基準測試組成,用於評估語言模型在各種任務上的性能,包括科學知識、常識推理和數學問題解決。
團隊成員
項目領導與協調
- Roberto Navigli:項目領導與協調;模型分析、評估與選擇,安全性與防護,對話設計。
模型開發
- Edoardo Barba:預訓練、後訓練、數據分析、提示工程。
- Simone Conia:預訓練、後訓練、評估、模型和數據分析。
- Pere-Llu√≠s Huguet Cabot:數據處理、過濾和去重、偏好建模。
- Luca Moroni:數據分析、評估、後訓練。
- Riccardo Orlando:預訓練過程和數據處理。
安全與防護
- Stefan Bejgu:安全與防護。
- Federico Martelli:合成提示生成、模型和安全分析。
- Ciro Porcaro:額外的安全提示。
- Alessandro Scir√®:安全與防護。
- Simone Stirpe:額外的安全提示。
- Simone Tedeschi:用於安全評估的英語數據集。
特別感謝
- Giuseppe Fiameni, Nvidia
- Sergio Orlandini, CINECA
致謝
這項工作得到了PNRR MUR項目PE0000013 - FAIR和CREATIVE PRIN項目的資助,後者由MUR國家重要研究項目計劃(PRIN 2020)資助。我們感謝CINECA在ISCRA計劃下授予的 “IscB_medit” 獎項,為我們提供了高性能計算資源和支持。
📄 許可證
本模型採用Apache 2.0許可證。
⚠️ 重要提示
本模型是一個聊天基礎模型,儘管採取了模型對齊和安全風險緩解策略,但仍可能存在以下問題:
- 過度代表某些觀點,而忽視其他觀點。
- 包含刻板印象。
- 包含個人信息。
- 生成以下內容:
- 種族主義和性別歧視內容。
- 仇恨、辱罵或暴力語言。
- 歧視性或偏見性語言。
- 可能不適用於所有場景的內容,包括色情內容。
- 出現錯誤,包括產生不正確的信息或歷史事實,就好像它們是真實的一樣。
- 生成無關或重複的輸出。
我們意識到當前預訓練大語言模型存在的偏差和潛在的問題/有害內容:更具體地說,作為(意大利語和英語)語言的概率模型,它們反映並放大了訓練數據中的偏差。有關此問題的更多信息,請參考我們的調查:
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
.png)
 Transformers Supports Multiple Languages
Transformers Supports Multiple Languages